CFA - Проверка статистических гипотез
Проверка статистических гипотез используется финансовыми аналитиками для проверки утверждений о значениях статистических финансовых показателей. Рассмотрим концепцию и методику проверки статистических гипотез в рамках изучения количественных методов по программе CFA.
Финансовые аналитики часто сталкиваются с конкурирующими идеями о том, как работают финансовые рынки. Некоторые из этих идей развиваются через личные исследования или опыт работы с рынками; другие появляются благодаря взаимодействию с коллегами; и многие другие появляются в результате публикаций в профессиональной литературе по финансам и инвестициям.
Но как может аналитик определить насколько истинны или ложны те или иные идеи?
Когда мы можем свести идею или предположение к определенному утверждению о значении величины, такому как среднее значение совокупности, идея становится статистически проверяемым утверждением или гипотезой.
Аналитик может захотеть исследовать такие вопросы, как:
- Отличается ли средняя доходность данного взаимного фонда от средней эталонной доходности?
- Изменится ли волатильность доходности акции, после того как эта акция будет добавлена в рыночный индекс акций?
- Влияет ли разница между ценами продажи и покупки акции, связанная с числом дилеров, на рынок этой акции?
- Поддерживают ли данные национального рынка облигаций прогноз, полученный на основе экономической теории о временной структуре процентных ставок (связь между доходностью и сроком погашения)?
Для решения этих вопросов, мы используем концепцию и методы проверки статистических гипотез.
Проверка статистических гипотез (англ. 'hypothesis testing') является частью статистического вывода, и представляет собой процесс принятия суждений о более крупной группе (совокупности) на основе небольшой фактически наблюдаемой группе (выборке).
Концепции и методы проверки гипотез обеспечивают объективные средства для оценки того, подтверждают ли имеющиеся доказательства гипотезу. После статистической проверки гипотезы мы должны иметь четкое представление о вероятности того, верна ли гипотеза или нет.
Проверка статистических гипотез была мощным инструментом в научном развитии инвестиций. Как написал Роберт Л. Кан (Robert L. Kahn) из Института социальных исследований (Анн-Арбор, штат Мичиган):
«Мельница науки перемалывает только тогда, когда гипотезы и данные находятся в непрерывном и тесном контакте».
Основные акценты этого чтения сосредоточены на основах проверки гипотез и проверке гипотез, касающихся среднего значения и дисперсии, - двух величин, весьма часто использующихся в инвестициях.
Сначала мы приведем обзор процедуры проверки гипотез. Затем обратимся проверке гипотез о среднем, гипотез о разнице между средними и среднем значении разности. В следующем разделе этого чтения, мы рассмотрим проверку гипотез о дисперсии и различиях между дисперсиями, а также проверку гипотез о значении коэффицента корреляции.
В завершение мы рассмотрим непараметрические методы статистического вывода.
Проверка гипотезы, как мы уже упоминали, является частью области статистики, известной как статистический вывод. Традиционно область статистического вывода имеет два направления: статистическая оценка и проверка гипотез.
Статистическая оценка отвечает вопрос:
«Чему равно значение этого параметра (например, среднего значения по совокупности)?»
Ответ на этот вопрос дается в виде доверительного интервала, построенного вокруг точечной оценки. В случае со средним значением, мы строим доверительный интервал для среднего значения совокупности вокруг выборочного среднего, полученного в результате точечной оценки.
Например, предположим, что выборочное среднее равно 50 и 95-процентный доверительный интервал для среднего населения составляет \(50 \pm 10\) (доверительный интервал составляет от 40 до 60). Если доверительный интервал правильно построен, то есть 95-процентная вероятность того, что интервал от 40 до 60 содержит среднее значение совокупности.
Вторая ветвь статистического вывода, проверка гипотез, имеет несколько иную направленность.
Проверка статистических гипотез отвечает на вопрос:
«Равно ли значение параметра (например, среднего значения по совокупности) 45 (или другому конкретному значению)?»
Утверждение «среднее совокупности равно 45» является гипотезой. Статистическая гипотеза (англ. 'hypothesis') определяется как утверждение об одной или нескольких совокупностях.
Этот раздел посвящен концепции проверки гипотез. Процесс проверки гипотезы является частью строгого подхода к получению знаний, известного как научный метод (англ. 'scientific method').
Научный метод начинается с наблюдений и формулировки теории организации и объяснения наблюдений. Мы судим о правильности теории по ее способности давать точные прогнозы - например, предсказывать результаты новых наблюдений.
Если прогнозы верны, мы продолжаем поддерживать теорию, как возможно правильное объяснение наших наблюдений. Когда в результатах наблюдений важна оценка риска, как в области финансов, мы можем попытаться сделать объективное, основанное на вероятности, суждение о том, поддерживают ли новые данные прогноз.
Проверка статистических гипотез играет ключевую роль, когда важна оценка риска.
В своей ежедневной работе финансовый аналитик может сталкиваться с вопросами, на которые он может дать ответы различного качества.
Когда аналитик правильно формулирует проверяемую гипотезу, проверяет ее и составляет отчет о проверке гипотезы, он следует нормам научного метода.
Конечно, логика аналитика, экономическое обоснование, источники информации, и, возможно, другие факторы также оказывают определенное влияние на качество ответа на заданный вопрос.
См. работу Freeley и Steinberg (2008) для обсуждения влияния критического мышления на мотивированное принятие решений.
Мы начнем изучение проверки гипотез со следующего списка из семи шагов.
Этапы проверки статистических гипотез.
Этапы проверки гипотезы заключаются в следующем:
- Формулировка гипотезы.
- Определение соответствующей тестовой статистики (статистического критерия) и ее распределения вероятностей.
- Определение уровня значимости.
- Формулировка правила принятия решения.
- Сбор данных и расчет статистического критерия.
- Принятие статистического решения.
- Принятие экономического или инвестиционного решения.
Мы расскажем о каждом из этих этапов, используя в качестве иллюстрации проверку гипотезы о премии за риск для американских акций. Описанный процесс представляет собой традиционный подход к проверке гипотез.
В завершении мы рассмотрим часто используемую альтернативу этих шагов - подход, основанный на p-значении.
1 этап. Формулировка гипотезы.
Первым шагом в проверке гипотезы является формулировка гипотезы. Мы всегда формулируем две гипотезы: нулевую гипотезу (или нуль), обозначаемую как \(H_0\), и альтернативную гипотезу, обозначаемую как \(H_a\).
Определение нулевой гипотезы.
Нулевая гипотеза - это гипотеза, которую нужно проверить. Например, мы могли бы предположить, что среднее по совокупности премии за риск для американских акций меньше или равно нулю.
Нулевая гипотеза (нуль, англ. 'null hypothesis') - это утверждение, которое считается истинным, если только используемая для проверки гипотезы выборка не дает убедительные доказательства того, что нулевая гипотеза неверна. Когда такие доказательства присутствуют, мы переходим к альтернативной гипотезе.
Определение альтернативной гипотезы.
Альтернативная гипотеза (альтернатива или конкурирующая гипотеза, англ. 'alternative hypothesis') - это гипотеза, которая принимается, когда нулевая гипотеза отвергается. Наша альтернативная гипотеза заключается в том, что среднее по совокупности премии за риск для американских акций больше нуля.
Предположим, что наш вопрос касается значения параметра совокупности \(\theta\), по отношению к одному возможному значению параметра, \(\theta_0\) (они читаются, соответственно, как «тета» и «тета ноль").
Греческие буквы, такие как \(\sigma\), зарезервированы для параметров совокупности. Римские курсивные буквы, например, \(s\), используются для выборочных статистик.
Примерами параметра совокупности являются среднее по совокупности \(\mu\) и дисперсия совокупности \(\sigma^2\). Мы можем сформулировать три различные пары нулевых и альтернативных гипотез и обозначить их согласно утверждению альтернативной гипотезы.
Формулировки гипотез.
Мы можем сформулировать нулевые и альтернативные гипотезы тремя различными способами:
- 1-я формулировка: \(H_0: \ \theta = \theta_0\) (нулевая гипотеза) и \(H_a: \ \theta \neq \theta_0\) (альтернативная гипотеза «не равно»).
- 2-я формулировка: \(H_0: \ \theta \leq \theta_0\) (нулевая гипотеза) и \(H_a: \ \theta > \theta_0\) (альтернативная гипотеза «больше чем»).
- 3-я формулировка: \(H_0: \ \theta \geq \theta_0\) (нулевая гипотеза) и \(H_a: \ \theta < \theta_0\) (альтернативная гипотеза «меньше, чем»).
В нашем примере с американскими акциями, \(\theta = \mu_{RP} \), что представляет собой среднее по совокупности премии за риск для американских акций. Кроме того, \(\theta_0 = 0 \), и мы используем вторую из указанных выше трех пар гипотез.
1-я формулировка представляет собой двустороннюю проверку гипотезы (англ. ' two-sided hypothesis test' или 'two-tailed hypothesis test'): Мы отвергаем нуль в пользу альтернативы, если данные свидетельствуют о том, что параметр совокупности либо меньше, либо больше, чем \(\theta_0 \).
В отличие от этого, 2-я и 3-я формулировки являются односторонней проверкой гипотезы (англ. 'one-sided hypothesis test' или 'one-tailed hypothesis test').
В формулировках 2 и 3 мы отвергаем нуль только тогда, когда данные свидетельствуют о том, что параметр совокупности соответственно, либо больше, либо меньше, чем \(\theta_0 \). Альтернативная гипотеза имеет только одну сторону.
Обратите внимание, что в каждом из описанных выше случаев, мы формулируем нулевые и альтернативные гипотезы так, что они учитывают все возможные значения параметра. В формулировке 1, например, параметр или равен гипотетическому значению \(\theta_0 \) (по нулевой гипотезе) или не равен гипотетическому значению \(\theta_0 \) (по альтернативной гипотезе).
Эти два утверждения логически исчерпывают все возможные значения параметра.
Несмотря на то, что формулировать гипотезы можно различными способами, мы всегда проводим проверку нулевой гипотезы в точке равенства, \(\theta = \theta_0 \). Если нуль это \(H_0: \ \theta = \theta_0\), \(H_0: \ \theta \leq \theta_0\) или \(H_0: \ \theta \geq \theta_0\), мы на самом деле проверяем \(\theta = \theta_0 \). Логика проста.
Предположим, что гипотетическое значение параметра равно 5.
Рассмотрим нулевую гипотезу \(H_0: \ \theta \leq 5\), с альтернативной гипотезой «больше чем» \(H_a: \ \theta > 5\) .
Если у нас есть достаточно доказательств, чтобы отклонить \(H_a: \ \theta = 5\) в пользу \(H_a: \ \theta > 5\), то у нас, безусловно, также есть достаточные доказательства, чтобы отвергнуть гипотезу о том, что параметр \(\theta\) равен некоторому меньшему значению, например, 4.5 или 4.
Напомним, что расчет для проверки нулевой гипотезы является одинаковым для всех трех формулировок. Различия в трех формулировках мы увидим в ближайшее время, - они заключаются в определении того, следует ли отклонить нулевую гипотезу.
Как мы выбираем нулевые и альтернативные гипотезы?
Вероятно, наиболее распространенными являются альтернативные гипотезы «не равно». Мы отвергаем нуль, поскольку данные свидетельствуют о том, что параметр больше или меньше, чем \(\theta_0\).
Иногда, однако, у нас могут быть условия, имеющие вид «ожидаем», «подозреваем» или «надеемся на то, что», которые означают, что мы хотим найти благоприятные доказательства.
В этом случае, мы можем сформулировать альтернативную гипотезу, как утверждение о том, что это условие является истинным. При этом нулевой гипотезой будет утверждение о том, что это условие не истинно. Если данные подтверждают отклонение нуля и принятие альтернативы, то мы статистически подтвердили наши ожидания того, что было истиной.
Например, экономическая теория предполагает, что инвесторы требуют положительную премию за риск по акциям (премия за риск определяется как ожидаемая доходность акций за вычетом безрисковой ставки).
Следуя принципу с формулировки альтернативы в виде условия «надеемся на то, что», сформулируем следующие гипотезы:
- \(H_0:\) Среднее по совокупности премии за риск для американских акций меньше или равно 0.
- \(H_a:\) Среднее по совокупности премии за риск для американских акций положительно.
Обратите внимание, что альтернативные гипотезы «больше чем» и «меньше чем» отражают убеждения исследователя сильнее, чем альтернативная гипотеза «не равно».
Для того, чтобы подчеркнуть свое нейтральное отношение к гипотезам, исследователь может иногда выбрать альтернативную гипотезу «не равно», когда выбор односторонней альтернативной гипотезы также разумен.
2 этап. Определение тестовой статистики (статистического критерия) и ее распределения вероятностей.
Второй этап проверки гипотез заключается в определении соответствующей тестовой статистики и ее распределения вероятностей.
Определение тестовой статистики.
Тестовая статистика, тест-статистика или статистический критерий (англ. 'test statistic') является величиной, рассчитанной на основе выборки, значение которой является основанием для принятия решения о том, следует ли отклонить нулевую гипотезу.
Средоточием нашего статистического решения является значение тестовой статистики. Очень часто (во всех случаях, которые мы рассмотрим в этом чтении) тестовая статистика имеет следующий вид:
\( \Large \stBf{Тестовая}{статистика} = { \stRm{Выборочная}{статистика} \ - \ \stRm{Значение параметра}{совокупности при $H_0$} \over \text{Стандартная ошибка выборочной статистики}} \) (Формула 1)
Для нашей премии за риск, например, интересующий параметр совокупности - это средняя по совокупности премия за риск \(\mu_{RP}\). Мы обозначаем гипотетическое значение среднего по совокупности населения для \(H_0\) как \(\mu_0\). Переформулировав гипотезу с использованием символов, мы проверяем нуль \(H_0: \mu_{RP} \leq \mu_0 \) и альтернативу \(H_a: \mu_{RP} > \mu_0 \).
Однако, поскольку в соответствии с нулем мы проверяем условие \( \mu_0 = 0\), то мы пишем \(H_0: \mu_{RP} \leq 0 \) и \(H_a: \mu_{RP} > 0 \).
Выборочное среднее обеспечивает оценку среднего по совокупности. Таким образом, мы можем использовать выборочное среднее премии за риск \( \overline X_{RP}\), рассчитанное на основе исторических данных, в качестве выборочной статистики в Формуле 1.
Стандартное отклонение выборочной статистики, известное как «стандартная ошибка» статистики, является знаменателем в Формуле 1.
В этом примере выборочной статистикой является выборочное среднее. Для выборочного среднего \( \overline X \), рассчитанного по выборке, отобранной из совокупности со стандартным отклонением \( \sigma \), стандартная ошибка определяется по одной из двух формул:
\(\large \dst
\sigma_{\overline X} = {\sigma \over \sqrt n} \) (Формула 2)
если нам известно стандартное отклонение совокупности \(\sigma\), или
\(\large \dst
s_{\overline X} = {s \over \sqrt n} \) (Формула 3)
когда мы не знаем стандартное отклонение совокупности и нам необходимо использовать стандартное отклонение выборки \(s\) оценки стандартной ошибки.
В этом примере, поскольку мы не знаем стандартное отклонение совокупности, порождающей доходность, мы используем Формулу 3.
Таким образом, тестовая статистика определяется по формуле:
\( \large \dst
{\overline X_{RP} - \mu_0 \over s_{\overline X}} = {\overline X_{RP} - 0 \over s \big / \sqrt n } \)
Заменяя \(\mu_0\) на 0, мы используем тот уже отмеченный факт, что мы тестируем любую нулевую гипотезу в точке равенства, а также тот факт, что здесь \(\mu_0 = 0\).
Итак, мы определили тестовую статистику, чтобы проверить нулевую гипотезу.
Какому распределению вероятностей она соответствует?
В этом чтении мы будет использовать четыре распределения вероятности для тестовых статистик:
- t-распределение Стьюдента (для t-теста);
- Стандартное нормальное или z-распределение (для z-теста);
- Распределение хи-квадрат (\( \chi^2 \)) (для хи-квадрат теста); а также
- F-распределение (для F-теста).
Мы обсудим детали этих вариантов позже, но предположим, что мы можем провести z-тест, основанный на центральной предельной теореме, потому что наша выборка американских акций имеет много наблюдений.
Выборка, которую мы будем использовать для этого примера, содержит 118 наблюдений.
В итоге, тестовая статистика для проверки гипотезы о средней премии за риск равна \( \overline X_{RP} \big / s_{\overline X}\).
Мы можем выполнить z-тест, поскольку мы можем правдоподобно предположить, что тестовая статистика следует стандартному нормальному распределению.
3 этап. Определение уровня значимости.
Третьим этапом проверки гипотез является определение уровня значимости. Когда тестовая статистика рассчитана, возможны два действия:
- Мы отвергаем нулевую гипотезу или
- Мы не отвергаем нулевую гипотезу.
Выбор действия основан на сравнении вычисленной тестовой статистики с заданным возможным значением или значениями. Значения, которые мы выбираем, основаны на выбранном уровне значимости. Уровень значимости отражает то, какие основанные на выборке доказательства нам необходимы, чтобы отвергнуть нуль.
По аналогии с судом, необходимая доказательная база может меняться в зависимости от характера гипотез и серьезности последствий совершения ошибки.
Возможны четыре результата при проверке нулевой гипотезы:
- Мы отвергаем ложную нулевую гипотезу. Это правильное решение.
- Мы отвергаем истинную нулевую гипотезу. Это называется ошибкой I рода (англ. 'Type I error').
- Мы не отвергаем ложную нулевую гипотезу. Это называется ошибкой II рода (англ. 'Type II error').
- Мы не отвергаем истинную нулевую гипотезу. Это правильное решение.
Проиллюстрируем эти результаты в Таблице 1.
|
Решение |
Ситуация |
|
|---|---|---|
|
\(H_0\) Истина |
\(H_0\) Ложь |
|
|
\(H_0\) не отвергается |
Правильное решение |
Ошибка II рода |
|
\(H_0\) отвергается (принимается \(H_a\)) |
Ошибка I рода |
Правильное решение |
Когда мы принимаем решение при проверке гипотезы, мы рискуем допустить ошибку I или II рода. Это взаимоисключающие ошибки:
- Если мы ошибочно отвергаем нуль, мы можем допустить только ошибку I рода.
- Если мы ошибочно не отвергаем нуль, мы можем допустить только ошибку II рода.
Вероятность ошибки I рода при проверке гипотезы обозначается греческой буквой альфа: \(\alpha\). Эта вероятность также известна как уровень значимости проверки (англ. 'level of significance').
Например, уровень значимости 0.05 для проверки означает, что есть 5-процентная вероятность отклонения истинной нулевой гипотезы.
Вероятность ошибки II рода обозначается греческой буквой бета: \(\beta\).
Управление вероятностью ошибок двух типов предполагает компромисс. При прочих равных, если мы уменьшаем вероятность ошибки I рода, задав меньший уровень значимости (скажем, 0.01, а не 0.05), мы увеличиваем вероятность совершить ошибку II рода, потому что мы отвергаем нуль реже, в том числе, когда он является ложным.
Единственным способом уменьшить вероятность ошибок обоих типов одновременно является увеличение размера выборки \(n\).
Количественный компромисс между двумя типами ошибок на практике, как правило, невозможен, потому что вероятность ошибки II рода очень трудно определить количественно.
Рассмотрим пример с парой гипотез: \(H_0: \ \theta \leq 5\) и \(H_a: \ \theta > 5\).
Поскольку каждое истинное значение \(\theta\) больше 5 делает нулевую гипотезу ложной, каждое значение \(\theta\) больше 5 имеет различную \(\beta\) (вероятность ошибки II рода).
В отличие от этого, нам достаточно только констатировать вероятность ошибки I рода при \(\theta = 5\). Таким образом, как правило, мы указываем только вероятность ошибки I рода, когда выполняем проверку гипотезы.
В то время как уровень значимости проверки является вероятностью ошибочно отвергнуть нулевую гипотезу, то мощностью критерия или мощностью проверки (англ. 'power of a test') является вероятность правильного отклонения нулевой гипотезы - то есть вероятность отвергнуть нуль, если он ложный.
Когда при проведении проверки имеется более одной статистики критерия, мы должны предпочесть самую мощную из них, при прочих равных условиях.
Тем не менее, у нас не всегда есть информация об относительной мощности критерия для конкурирующих статистик критерия.
В итоге, стандартный подход к проверке гипотез включает только определение уровня значимости (вероятности ошибки I рода). Наиболее целесообразно устанавливать этот уровень значимости до расчета тестовой статистики (статистики критерия). Если мы указываем его после вычисления тестовой статистики, на нас может повлиять результат расчета, что умаляет объективность проверки.
Мы можем использовать три наиболее распространенных уровня значимости для проведения проверки гипотезы: 0.10, 0.05 и 0.01.
Если мы можем отклонить нулевую гипотезу на уровне значимости 0.10, то у нас есть доказательства того, что нулевая гипотеза неверна.
Если мы можем отклонить нулевую гипотезу на уровне значимости 0.05, то у нас есть убедительные доказательства того, что нулевая гипотеза неверна.
И если мы можем отклонить нулевую гипотезу на уровне значимости 0.01, то у нас есть очень убедительные доказательства того, что нулевая гипотеза неверна.
Для нашего примера с премией за риск, мы установим уровень значимости 0.05.
4 этап. Формулировка правила принятия решения.
Четвертый этап проверки гипотезы заключается в формулировке правила принятия решения (англ. 'decision rule').
Общий принцип формулируется просто.
Когда мы проверяем нулевую гипотезу, если мы находим, что рассчитанное значение статистики критерия (тестовой статистики) является экстремальным или более экстремальным, чем заданное значение или значения, определенные установленным уровнем значимости \(\alpha\), то мы отвергаем нулевую гипотезу. Мы говорим, что результат является статистически значимым (англ. 'statistically significant').
В противном случае, мы не отвергаем нулевую гипотезу, и говорим, что результат не является статистически значимым. Значение или значения, с которым мы сравниваем вычисленную статистику критерия, чтобы принять наше решение, являются точками отклонения (критическими значениями) для проверки гипотезы.
Определение критического значения для статистики критерия.
Критическое значение или точка отклонения (англ. 'critical value') для тестовой статистики (статистики критерия) представляет собой значение, с которой сравнивается вычисленная тестовая статистика, чтобы решить, следует ли отклонять или не отклонять нулевую гипотезу.
Для односторонней проверки, мы указываем критическое значение, используя символ для тестовой статистики с индексом \(\alpha\), обозначающим заданную вероятность ошибки I рода, например, \(z_\alpha\).
Для двусторонней проверки, мы указываем критическое значение \(z_{\alpha/2}\).
Для того, чтобы проиллюстрировать применение критических значений, предположим, что мы используем z-тест и выбрали уровень значимости 0.05.
Для проверки пары гипотез \(H_0: \ \theta = \theta_0\) и \(H_a: \ \theta \neq \theta_0\), существуют два критических значения, - одно отрицательное и одно положительное.
Для двухсторонней проверки при уровне значимости 0.05, суммарная вероятность ошибки I рода должна быть равна 0.05. Таким образом, 0.05 / 2 = 0.025 вероятности должно быть в каждом хвосте распределения тестовой статистики при нулевой гипотезе.
Следовательно, двумя критическими значениями будут \(z_{0.025} = 1.96\) и \(-z_{0.025} = -1.96\). Пусть \(z\) является вычисленным значением тестовой статистики. Мы отвергаем нуль, если находим, что \(z < -1.96\) или \(z > 1.96\). И мы не отвергаем нуль, если \(-1.96 \leq z \leq 1.96\).
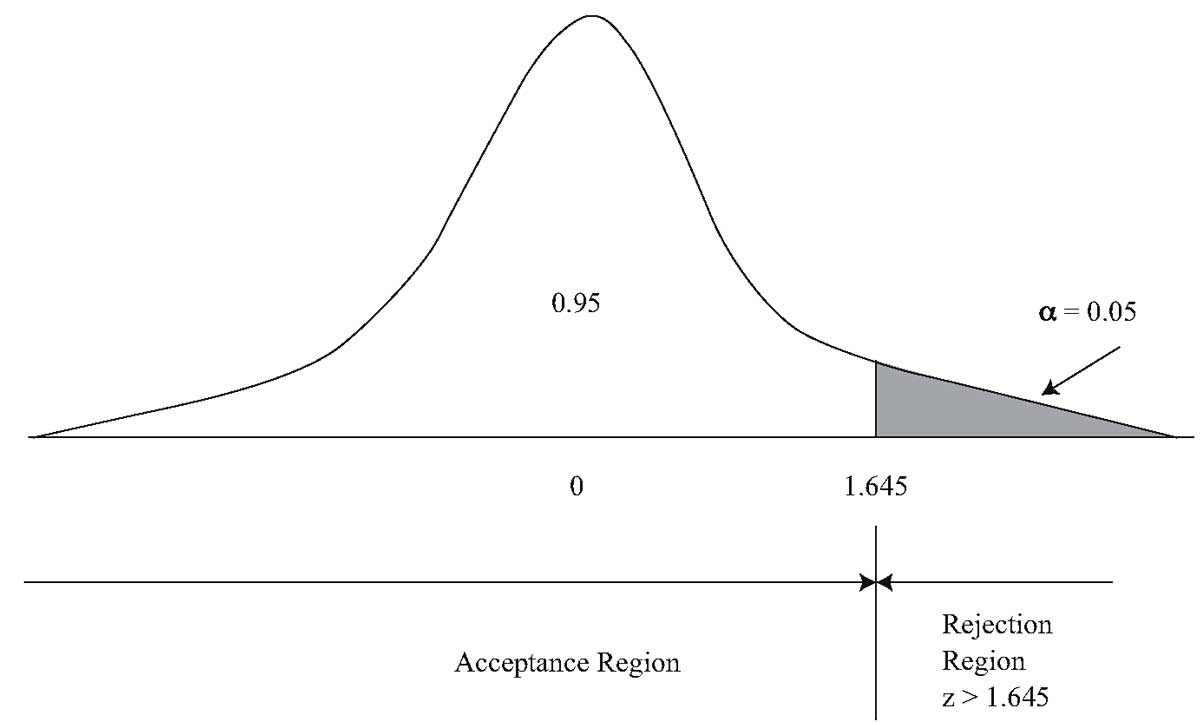
Для проверки пары гипотез \(H_0: \ \theta \leq \theta_0\) и \(H_a: \ \theta > \theta_0\) при уровне значимости 0.05, критическим значением будет \(z_{0.05} = 1.645\). Мы отвергаем нулевую гипотезу, если \(z > 1.645\). Значение стандартного нормального распределения таково, что 5% результатов лежат правее точки \(z_{0.05} = 1.645\).
Для проверки пары гипотез \(H_0: \ \theta \geq \theta_0\) и \(H_a: \ \theta < \theta_0\), критическим значением будет \(-z_{0.05} = -1.645\). Мы отвергаем нулевую гипотезу, если \(z < -1.645\).
График 2 иллюстрирует проверку \(H_0: \ \mu = \mu_0\) и \(H_a: \ \mu \neq \mu_0\) при уровне значимости 0.05 с использованием z-теста.
Термин «область принятия гипотезы» (англ. 'acceptance region') является традиционным названием для множества значений тестовой статистики, при которых мы не отвергаем нулевую гипотезу.
Традиционное название, однако, неточное. Мы должны избегать использования таких фраз, как «принять нулевую гипотезу», потому что такое утверждение подразумевает неоправданно большую степень убежденности в нуле, когда мы не отвергаем его.
По обеим сторонам от области принятия решения находятся области отклонения или критические области (англ. 'rejection region' или 'critical region').
Если нулевая гипотеза заключается в том, что \( \mu = \mu_0 \) истинно, тестовая статистика имеет 2.5-процентный шанс попадания в левую критическую область и 2.5-процентный шанс попадания в правую критическую область.
Любое вычисленное значение тестовой статистики, которое попадает в любую из этих двух областей, заставляет нас отвергнуть нулевую гипотезу при уровне значимости 0.05. Критические значения 1.96 и -1.96 рассматриваются как разделительные линии между областями принятия и отклонения гипотезы.
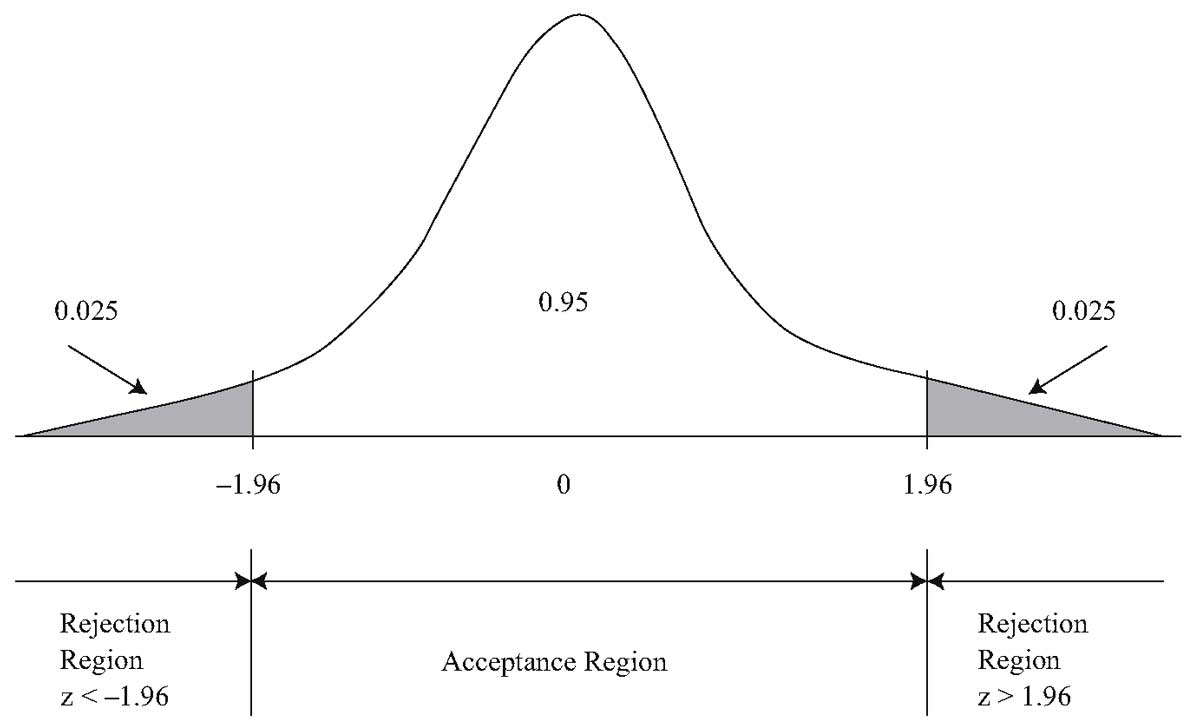
График 2 дает хорошую возможность подчеркнуть взаимосвязь между доверительными интервалами и проверкой гипотез. 95-процентный доверительный интервал для среднего по совокупности \(\mu\), основанного на выборочном среднем \(\overline X\), задается диапазоном от \(\overline X - 1.96s_{\overline X}\) до \(\overline X + 1.96s_{\overline X}\), где \(s_{\overline X}\) является стандартной ошибкой выборочного среднего (Формула 3).
Так же, как и при проверке гипотезы, мы можем использовать этот доверительный интервал, основанный на стандартном нормальном распределении, когда у нас есть большая выборка.
Альтернативная проверка гипотезы и доверительный интервал используют t-распределение. Мы рассмотрим эти концепции в следующем разделе.
Теперь рассмотрим одно из условий для отклонения нулевой гипотезы:
\( \dst {\overline X - \mu_0 \over s_{\overline X}} > 1.96\)
Здесь \(\mu_0\) является гипотетическим значением среднего по совокупности. Условие гласит, что отклонение гипотезы является оправданным, если тестовая статистика превышает 1.96.
Умножив обе стороны неравенства на \(s_{\overline X}\), мы получим \( \overline X - \mu_0 > 1.96 s_{\overline X}\), или после преобразования, \( \overline X - 1.96 s_{\overline X} > \mu_0\), что можем также записать в виде \( \mu_0 < \overline X - 1.96 s_{\overline X}\).
Это выражение означает, что если гипотетическое среднее по совокупности \(\mu_0\), меньше нижнего предела 95-процентного доверительного интервала, основанного на выборочном среднем, мы должны отвергнуть нулевую гипотезу при уровне значимости 5% (тестовая статистика попадает в критическую область справа).
Теперь мы можем взять другое условие для отклонения нулевой гипотезы:
\( \dst {\overline X - \mu_0 \over s_{\overline X}} < -1.96\)
и, используя алгебру, как и ранее, мы преобразуем его к виду:
\( \dst \mu_0 > \overline X - 1.96 s_{\overline X}\)
Если гипотетическое среднее по совокупности больше, чем верхний предел 95-процентного доверительного интервала, мы отвергаем нулевую гипотезу при уровне значимости 5% (тестовая статистика попадает в критическую область слева).
Таким образом, уровень значимости в двусторонней проверке гипотезы можно интерпретировать точно так же, как доверительный интервал \(1 - \alpha\).
Таким образом, когда гипотетическое значение параметра совокупности для нулевой гипотезы находится вне соответствующего доверительного интервала, то нулевая гипотеза отвергается. Мы могли бы использовать доверительные интервалы для проверки гипотез, но на практике финансовые аналитики, как правило, этого не делают.
Вычисление тестовой статистики (одно число, по сравнению с двумя числами для обычного доверительного интервала) более эффективно. Также, на практике аналитики редко сталкиваются с односторонними доверительными интервалами.
Кроме того, только вычислив тестовую статистику, мы можем получить p-значение, полезный показатель значимости результатов (мы обсудим p-значение далее).
Вернемся к нашей проверке премии за риск.
Мы сформулировали гипотезы \(H_0: \mu_{RP} \leq 0\) и \(H_a: \mu_{RP} > 0\). Мы определили тестовую статистику как \( \overline X_{RP} / s_{\overline X}\) и определили, что она следует стандартному нормальному распределению.
Таким образом, мы выполняем односторонний z-тест.
Мы определили уровень значимости 0.05. Для этого одностороннего z-теста, критическая точка при уровне значимости 0.05 составляет 1.645. Мы отвергаем нуль, если вычисленная z-статистика больше, чем 1.645.
График 3 иллюстрирует эту проверку.
5 этап. Сбор данных и расчет тестовой статистики.
Пятый шаг в проверке гипотез заключается в сборе данные и расчете тестовой статистики. Качество наших выводов зависит не только от уместности статистической модели, но и от качества данных, которые мы используем при проведении проверки.
В первую очередь мы должны проверить данные на наличие ошибок измерений. Нам также необходимо учесть другие проблемы, в том числе систематическую ошибку выборки и систематическую ошибку временного периода.
Систематическая ошибка выборки - это смещение выборки, связанное с систематическим исключением некоторых элементов совокупности в соответствии с определенным признаком.
Одним из типов систематической ошибки выборки является систематическая ошибка выжившего. Например, если мы определим нашу выборку, как облигации взаимных фондов США, которые продолжают деятельность в настоящее время, и мы сделаем выборку доходности только по этим фондам, мы будем систематически исключать фонда, которые не выжили (прекратили деятельность) к настоящему моменту.
Прекратившие деятельность фонды, скорее всего, в среднем хуже оставшихся фондов. В результате, эффективность фондов, рассчитанная на основе этой выборки, может быть смещена вверх.
Систематическая ошибка временного периода связана с вероятностью того, что когда мы используем выборку из временных рядов, наш статистический вывод может быть чувствительным к начальным и конечным датам периода выборки.
В нашей гипотезе о премии за риск мы имеем дело с американскими акциями. Согласно Dimson, Marsh и Staunton (2018) за период с 1900 по 2017 год включительно (118 ежегодных наблюдений), среднеарифметическая премия за риск для американских акций по отношению к доходности облигаций \(\overline X_{RP}\) составила 7.5% в год.
Выборочное стандартное отклонение годовой премии за риск составило 19.5%. Используя Формулу 3, найдем стандартную ошибку выборочного среднего:
\( \dst s_{\overline X} = s \big / \sqrt n = 19.5\% / \sqrt {118} \) = 1.795%.
Тестовая статистика равна:
\( \dst z = \overline X_{RP} \big / s_{\overline X}\) = 7.5%/1.795% = 4.18.
6 этап. Принятие статистического решения.
Шестой этап проверки гипотезы означает принятие статистического решения.
В нашем примере, поскольку тестовая статистика \(z = 4.18\) больше критического значения 1.645, мы отвергаем нулевую гипотезу в пользу альтернативной гипотезы о том, что премия за риск для американских акций является положительной.
Первые шесть шагов являются статистическими шагами. Наше итоговое решение принимается с использованием статистического решения.
7 этап. Принятие экономического или инвестиционного решения.
Седьмой и заключительный шаг в проверке гипотез заключается в принятии экономического или инвестиционного решения. Экономическое или инвестиционное решение принимает во внимание не только статистические решения, но и все соответствующие экономические вопросы.
На шестом этапе, мы нашли убедительные статистические доказательства того, что премия за риск для американских акций является положительной. Величина расчетной премии за риск, 7.5% в год, является также очень значимой экономически.
Исходя из этих соображений, инвестор может принять решение инвестировать часть средств в американские акции. Ряд нестатистических соображений, таких как толерантность инвестора к риску и его финансовое положение, может также повлиять на процесс принятия решений.
Предшествующее обсуждение поднимает проблему, которая часто возникает на этом этапе принятия решений. Мы часто находим, что небольшие различия между переменной величиной и ее гипотетическим значением являются статистически значимыми, но не значимыми экономически.
Например, мы можем проверить инвестиционную стратегию и отклонить нулевую гипотезу о том, что средняя доходность стратегии равна нулю на основе большой выборки.
Формула 1 показывает, что чем меньше стандартная ошибка выборочной статистики (делитель в формуле), тем больше значение тестовой статистики и тем больше шанс на то, что нулевая гипотеза будет отклонена, при прочих равных условиях. Стандартная ошибка уменьшается по мере увеличения размера выборки \(n\), так что при очень больших выборках, мы можем отклонить нулевую гипотезу.
Мы можем обнаружить, что, хотя стратегия обеспечивает статистически значимую положительную среднюю доходность, результаты не являются экономически значимыми, если учесть транзакционные издержки, налоги и риски.
Даже если мы приходим к выводу, что результаты стратегии являются экономически значимыми, мы должны изучить логику того, почему стратегия могла бы работать в будущем, прежде чем реализовывать ее фактически. Такие соображения нельзя включить в проверку гипотезы.
Перед тем как завершить тему процесса проверки гипотез, мы должны обсудить важный альтернативный подход, называемый подходом проверке гипотез с. Аналитики и исследователи часто включают в отчеты о проверке гипотез p-значение (также называемое предельным уровнем значимости, англ. 'marginal significance level').
Определение p-значения.
P-значение (p-уровень значимости или p-критерий, англ. 'p-value') является наименьшим уровнем значимости, при котором может быть отвергнута нулевая гипотеза.
Для значения тестовой статистики 4.18 в проверке гипотезы о премии за риск, с помощью функции электронной таблицы для стандартного нормального распределения, мы вычисляем р-значение 0.000015. Мы можем отклонить нулевую гипотезу на этом уровне значимости.
Чем меньше р-значение, тем сильнее доказательства против нулевой гипотезы и в пользу альтернативной гипотезы. P-значение для двухсторонней проверки того, что параметр равен нулю, часто генерируется автоматически с помощью статистических и эконометрических программ.
Мы можем использовать р-значение в рамках процедуры проверки гипотез, представленной выше, в качестве альтернативы критическим значениям.
Если р-значение меньше нашего заданного уровня значимости, мы отвергаем нулевую гипотезу. В противном случае, мы не отвергаем нулевую гипотезу.
Используя p-значение таким образом, мы приходим к такому же выводу, что и при использовании критических значений. Например, поскольку 0.000015 меньше 0.05, мы отвергаем нулевую гипотезу в проверке гипотезы о премии за риск.
P-значение, тем не менее, обеспечивает более точную информацию о силе доказательств, чем подход с использованием критических значений. P-значение 0.000015 указывает на то, что нулевая гипотеза отвергается на гораздо меньшем уровне значимости, чем 0.05.
Если один исследователь рассматривает вопрос, используя уровень значимости 0.05, а другой исследователь использует уровень значимости 0.01, читатель может столкнуться с проблемой, сравнивая полученные результаты.
Эта проблема породила подход к представлению результатов проверки гипотез, при котором указываются p-значения и не указывается спецификация уровня значимости (этап 3).
Интерпретация статистических результатов остается на усмотрение пользователя исследования. Этот подход к представлению результатов иногда называют подходом к проверке гипотез с использованием р-значения.
Davidson и MacKinnon (1993) оспорили достоинство этого подхода:
«Подход с использование p-значения по не обязательно заставит нас принять решение о нулевой гипотезе. Если мы получим p-значение равное, скажем, 0.000001, мы почти наверняка захотим отклонить нуль.
Но если мы получим p-значение равное, скажем, 0.04, или даже 0.004, мы не обязаны отклонять его. Мы можем просто отбросить результат прочь, как информацию, которая ставит под сомнение нулевую гипотезу, но сама по себе не убедительна.
Мы считаем, что это несколько агностическое отношение к статистическим проверкам, в которых p-значения рассматриваются просто как части информации, которую мы можем использовать, но можем и не использовать». (Стр. 80)