CFA - Исследование текстовых данных в проекте финансового прогнозирования
Рассмотрим этап исследования текстовых данных (исследовательский анализ, выбор и разработку признаков) в проекте финансового прогнозирования на основе машинного обучения, - в рамках изучения количественных методов по программе CFA (Уровень II).
Исследовательский анализ данных.
Исследовательский анализ данных (EDA, exploratory data analysis), выполненный на текстовых данных, дает представление о распределении слов в тексте.
Сначала выполняется подсчет количества повторяющихся слов во всех предложениях.
Полученные количества слов (токенов) можно использовать для изучения выбросов токенов - слов, которые наиболее часто и наиболее редко встречаются в текстах. Наиболее частые вхождения слов во всех предложениях из набора данных показаны в Иллюстрации 32.
Эти обычные слова будут удалены позднее, на этапе выбора признаков. Примечательно, что токены «million» и «currencysign» часто встречаются из-за финансового характера данных.
Иллюстрация 32. Наиболее часто встречающиеся токены в корпусе текстовых данных.
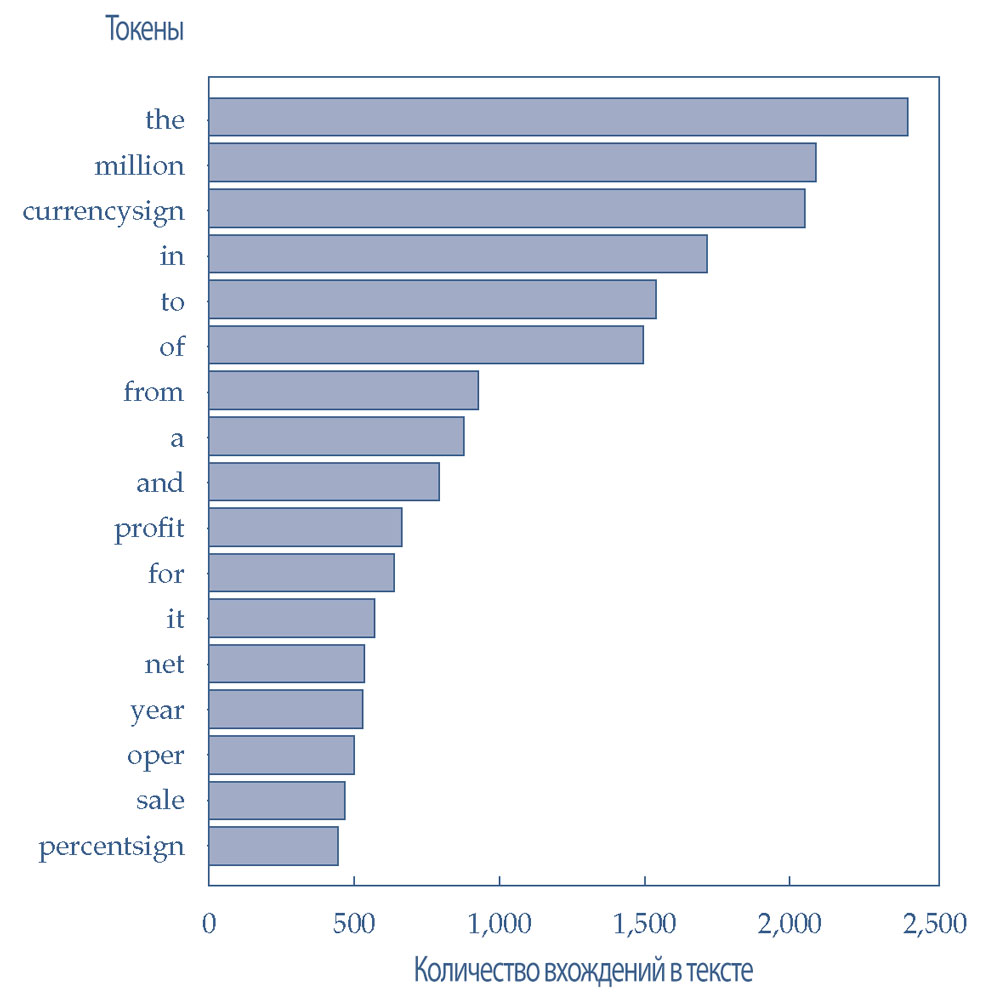
Наиболее часто встречающиеся токены в корпусе текстовых данных.
Наиболее частые слова в предложениях, отнесенные к отрицательным и положительным классам настроений показаны в Иллюстрации 33.
Наиболее часто встречающиеся слова схожи для обоих классов настроений. Это означает, что частоты малополезны для определения различий между классами настроений.
Этот вывод демонстрирует полезность удаления наиболее часто используемых токенов из мешка слов.
Иллюстрация 33. Наиболее часто используемые токены в двух классах настроений.
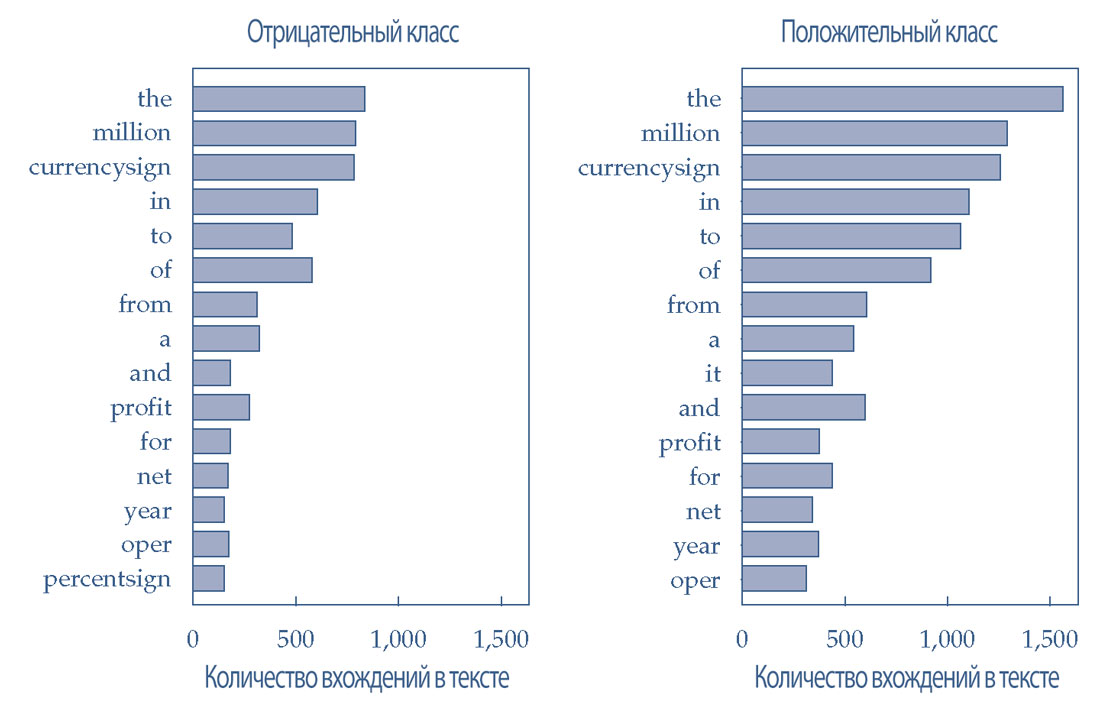
Наиболее часто используемые токены в двух классах настроений.
В Иллюстрации 34 показана гистограмма распределения длины предложений. Длина предложения (sentence length) определяется как количество символов в предложении, включая пробелы.
- Самое длинное предложение имеет 273 символа;
- самое короткое предложение имеет 26 символов; и
- среднее количество символов составляет около 120 (обозначено вертикальной пунктирной линией).
Хотя это распределение не оказывает прямого влияния на обучение модели, эта гистограмма визуально демонстрирует диапазон длины предложений и помогает определить любые чрезвычайно длинные или короткие предложения.
Эта гистограмма не выглядит необычной, поэтому удалять выбросы не нужно.
Иллюстрация 34. Гистограмма длины предложений со средней длиной предложения.
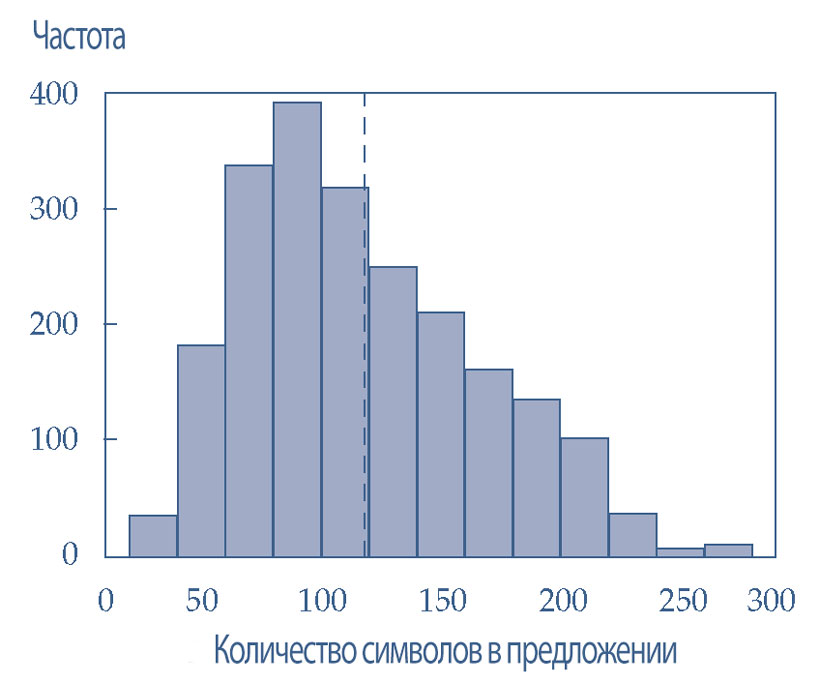
Гистограмма длины предложений со средней длиной предложения.
Облака слов (word clouds) - это удобный метод визуализации текстовых данных, поскольку облака слов обеспечивают быстрое понимание большого количества токенов и их соответствующих весов.
В Иллюстрации 35 показано облако слов для всех предложений в корпусе. Размеры шрифтов слов пропорциональны количеству вхождений каждого слова в корпус.
Точно так же в Иллюстрации 36 показано облако слов, разделенное на две половины:
- верхняя половина представляет предложения, отнесенные к классу отрицательных настроений;
- нижняя половина представляет предложения, отнесенные к классу положительных настроений;
Примечательно, что в облаке слов присутствуют некоторые очень отличительные стемы (базовые формы слов) и слова, например, «decreas» и «down» в отрицательной половине и «increas» и «rose» в положительной половине.
Далее выполняется процесс выбора признаков, который устраняет обычные (бесполезные) слова и выделяет полезные слова для лучшего обучения модели.
Иллюстрация 35. Облако слов для всего корпуса.

Облако слов для всего корпуса.
Иллюстрация 36. Облако слов, разделенное на две подгруппы корпуса.

Облако слов, разделенное на две подгруппы корпуса.
Выбор признаков для текстовых данных.
Исследовательский анализ данных выявил наиболее частые токены в текстах, которые потенциально могут добавить шум в процесс обучения модели ML.
В дополнение к частым токенам, многие редко встречающиеся токены, которые часто оказываются именами собственными, также не являются информативными для понимания настроения предложения.
Необходимо провести дальнейший анализ, чтобы решить, какие слова следует исключить.
Выбор признаков для текстовых данных включает в себя сохранение в мешке данных полезных токенов, которые являются информативными и помогают различать различные классы текстов, соответствующие положительным и отрицательным настроениям.
На данный момент мы имеем в общей сложности 44,151 неуникальный токен в 2,180 предложениях.
Частотный анализ (frequency analysis) обработанных текстовых данных помогает отфильтровать ненужные токены (или признаки) путем количественной оценки того, насколько важны токены в предложении и в корпусе в целом.
Частота слов или частота терминов (TF, term frequency) на уровне корпуса, также известная как частота коллекции (CF, collection frequency) - это количество раз, которое данное слово встречается во всем корпусе (то есть, коллекции предложений), разделенное на общее количество слов в корпусе.
Частоту терминов можно рассчитать и изучить, чтобы идентифицировать выбросы слов. Иллюстрация 37 показывает описательную статистику частоты терминов для слов на уровне коллекции.
Значения TF варьируются в диапазоне от 0 до 1, поскольку TF является отношением общего количества вхождений определенного слова к общему количеству слов в коллекции.
В Иллюстрации 37 также показана выборка слов с самыми высокими и самыми низкими значениями TF, чтобы можно было получить представление о том, какие слова встречаются на этих экстремальных частотах.
Иллюстрация 37. Сводная статистика TF для слов на уровне коллекции, образцы слов с экстремальными значениями TF и гистограмма значений TF.
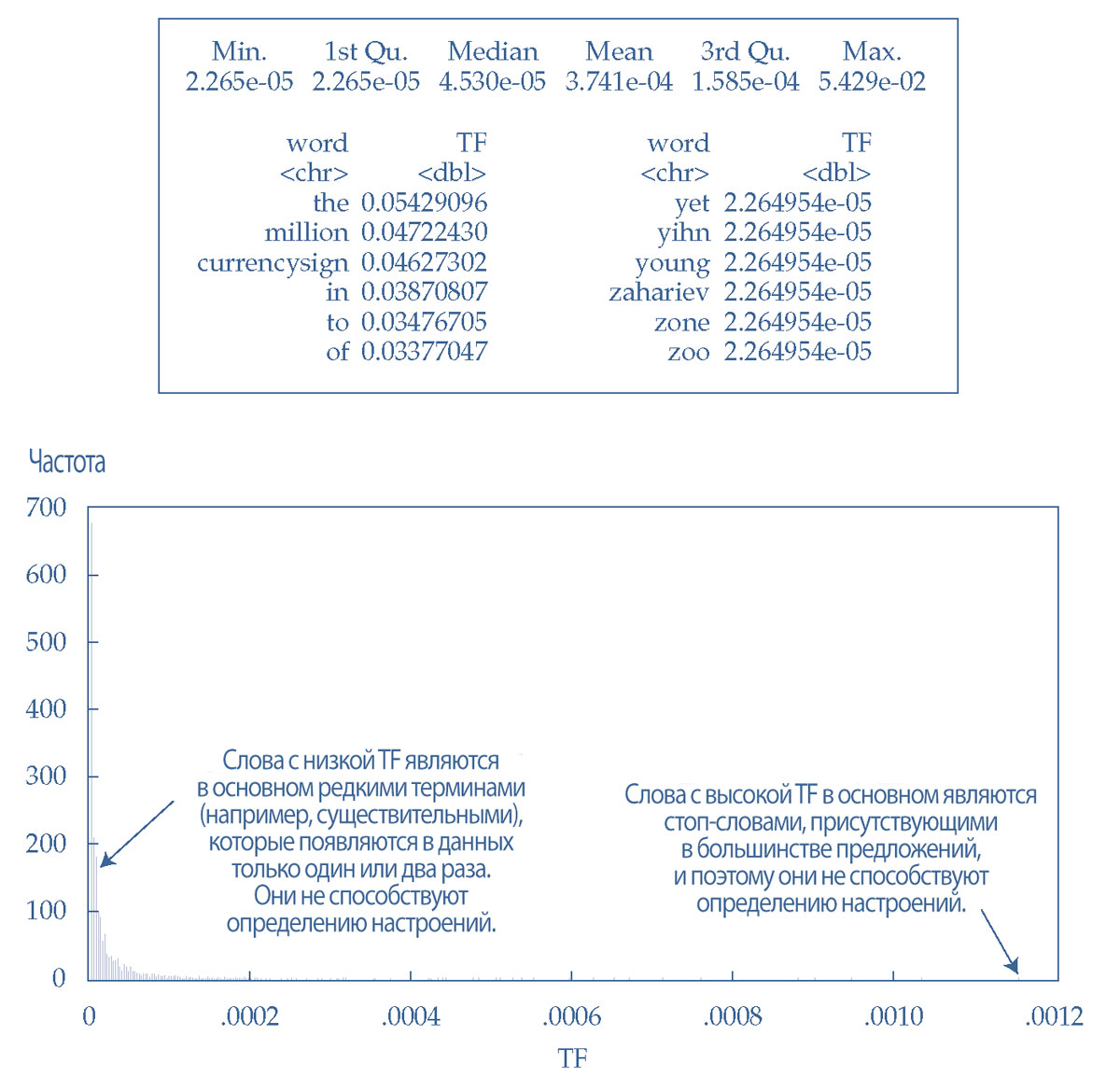
Расчет самых высоких и самых низких TF на уровне коллекции является общей стратегией для выявления шумных терминов.
Гистограмма в Иллюстрации 37 показывает длинный хвост с правой стороны, что означает общие термины, которые нужно удалить. Высокочастотные полосы слева показывают, что существует также много редких слов (например, тех, которые встречаются в данных только один или два раза).
Такие редкие термины не встречаются достаточно часто, чтобы их можно было использовать в качестве значимых признаков, и их обычно удаляют.
Слова с самой высокой TF в основном являются стоп-словами, которые бесполезны, потому что присутствуют в большинстве предложений и, следовательно, не способствуют выявлению настроений, встроенных в текст.
Слова с самыми низкими значениями TF - это в основном имена собственные или редкие термины, которые также не важны для значения текста.
В этом примере, после тщательного изучения слов с экстремальными частотами, слова с высокими значениями TF (> 99.5 процентиля, 14 слов) и низкими значениями TF (< 30 процентиля, 714 слов) удаляются перед формированием терм-документной матрицы (DTM).
В Иллюстрации 38 показано 14 слов с самыми высокими значениями TF (> 99.5 процентиля), которые являются пользовательскими (нестандартными) стоп-словами для этого проекта.
Иллюстрация 38. Четырнадцать нестандартных стоп-слов для проекта.
|
«the» |
«million» |
«currencysign» |
«in» |
«to» |
«of» |
«from» |
|
«and» |
«profit» |
«for» |
«it» |
«not» |
«year» |
«a» |
Чтобы построить DTM для обучения модели машинного обучения, необходимо рассчитать различные показатели TF, чтобы заполнить ими ячейки DTM.
Иллюстрация 39 показывает часть таблицы показателей TF, которая вычисляется для текстовых данных перед удалением нестандартных стоп-слов.
Иллюстрация 39. Образец вывода таблицы показателей частоты слов (TF).

Образец вывода таблицы показателей частоты слов (TF).
Эта таблица содержит следующие столбцы:
1. SentenceNo: уникальный идентификационный номер, присвоенный каждому предложению в том порядке, в котором они присутствуют в исходном наборе данных.
Например, предложение № 701 является предложением из строки 701 таблицы данных:
«the airlin estim that the cancel of it flight due to the closur of european airspac and the process of recommenc traffic have caus a the compani a loss of currencysign million includ the cost of strand passeng accommod».
2. TotalWordsInSentence: подсчет общего количества слов, присутствующих в предложении. Например, предложение № 701 имеет в общей сложности 39 слов.
3. Word: токен слова, которое присутствует в соответствующем предложении.
4. TotalWordCount: общее количество вхождений слова во всем корпусе или коллекции. Например, токен «the» встречается 2,397 раз во всей коллекции предложений. Следующую формулу можно использовать для вычисления TF на уровне коллекции:
TF (уровень коллекции) =
TotalWordCount / Общее количество слов в коллекции (10)
TF слова «the» на уровне коллекции рассчитывается как 2,397/44,151 = 0.05429096. Обратите внимание, что этот результат можно было заметить ранее в Иллюстрации 37.
5. WordCountInSentence: количество раз, которое токен встречается в соответствующем предложении. Например, токен «the» встречается шесть раз в предложении № 701.
6. SentenceCountWithWord: Количество предложений, в которых присутствует слово. Например, токен «the» присутствует в 1,453 предложениях.
7. TF (частота слов) на уровне предложения: количество раз, когда слово встречается в предложении, разделенное на общее количество слов в этом предложении.
Следующую формулу можно использовать для расчета TF на уровне предложения:
TF (уровень предложения) =
WordCountInSentence / TotalWordsInSentence (11)
Например, TF на уровне предложения для слова «the» в предложениях № 701 и 223 рассчитывается как 6/39 = 0.1538462 и 5/37 = 0.1351351, соответственно.
8. DF, Document frequency (частота документов): определяется как количество документов (то есть, предложений), которые содержат данное слово, деленное на общее количество предложений (здесь, 2,180).
Частота документов важна, поскольку слова часто встречаются в разных предложениях, не предоставляя при этом полезной информации в каждом предложении.
Следующую формулу можно использовать для расчета DF:
DF = SentenceCountWithWord / Общее количество предложений (12)
Например, DF слова «the» - это 1,453/2,180 = 0.6665138. Таким образом, 66.7% предложений содержат слово «the». Высокая DF указывает на высокую частоту слова в тексте.
9. IDF, Inverse Document Frequency (обратная частота документов): относительный показатель того, насколько уникальным является слово во всем корпусе. Его значение не связано напрямую с размером корпуса.
Следующую формулу можно использовать для вычисления IDF:
IDF = log(1 / DF). (13)
Например, IDF слова «the» - это log(1/0.6665138) = 0.4056945.
Низкая IDF указывает на высокую частоту слова в тексте.
10. TF-IDF: Чтобы получить полное представление о значении каждого слова, TF на уровне предложения умножается на IDF слова на уровне всего набора данных.
Более высокие значения TF-IDF указывают на слова, которые чаще встречаются в меньшем количестве документов. Это означает относительно более уникальные термины, которые важны для обучения модели.
И наоборот, низкое значение TF-IDF указывает на слова, которые встречаются во многих документах. Значения TF-IDF могут быть полезны для определения ключевых терминов в совокупности документов и могут служить значениями признаков слов для обучения модели ML.
Следующую формулу можно использовать для вычисления TF-IDF:
TF-IDF = TF \(\times\) IDF (14)
Например, TF-IDF токена «of» рассчитывается как
0.1666667 \(\times\) 0.7954543 = 0.13257571.
Аналогичным образом, в Иллюстрации 40 показаны высокие значения TF-IDF слов в текстовых данных перед удалением пользовательских (нестандартных) стоп-слов.
Иллюстрация 40. Образец вывода слов с высокими значениями TF-IDF.

Образец вывода слов с высокими значениями TF-IDF.
Значения TF или TF-IDF размещаются на пересечении предложений (строк) и терминов (столбцов) в терм-документной матрице (DTM).
В этом проекте значения TF используются в DTM, поскольку тексты являются предложениями, а не параграфами или другими более крупными частями текста.
Значения TF-IDF варьируются в зависимости от количества документов в наборе данных; следовательно, эффективность модели может варьироваться, если она применяется к набору данных всего с несколькими документами.
В дополнение к удалению нестандартных стоп-слов и редких терминов, одиночные буквы также удаляются, поскольку они не оказывают никакого влияния на определение настроения.
Разработка новых признаков.
В этом проекте n-граммы используются в качестве метода для разработки признаков. Использование n-грамм помогает понять настроение предложения в целом.
Как упоминалось ранее, цель этого проекта состоит в том, чтобы предсказать класс настроений (положительный и отрицательный) на основе финансовых текстов. В текстах есть как юниграммы, так и биграммы, и мешок слов (BOW) создается из них.
Токены биграмм полезны, чтобы сохранить логические отрицания в тексте, что жизненно важно для прогнозирования настроений.
Например, токены «not» и «good» или «no» и «longer», могут быть представлены в форме в одиночных токенов-биграмм, таких как «not_good» и «no_longer». Эти и аналогичные токены могут быть полезны для обучения модели машинного обучения и могут улучшить эффективность модели.
В Иллюстрации 41 показана выборка из 100 слов из мешка слов, содержащего как юниграммы, так и биграммы, после удаления пользовательских (нестандартных) стоп-слов, редких терминов и отдельных символов.
Обратите внимание, что мешок слов содержит такие токены, как increas, loss, loss_prior, oper_rose, tax_loss и sale_increas. Такие токены несут в себе информацию о встроенных в тексты настроениях и полезны для обучения модели.
Соответствующие показатели частоты слов для матрицы DTM вычислены на основе этого нового мешка слов.
Иллюстрация 41. Выборка из ста токенов из окончательного мешка слов на основе всего корпуса.
|
"last" |
"last_quarter" |
"quarter" |
"quarter_componenta" |
"componenta" |
|
"componenta_sale" |
"sale" |
"sale_doubl" |
"doubl" |
"doubl_same" |
|
"same" |
"same_period" |
"period" |
"period_earlier" |
"earlier" |
|
"earlier_while" |
"while" |
"while_move" |
"move" |
"move_zero" |
|
"zero" |
"zero_pre" |
"pre" |
"pre_tax" |
"tax" |
|
"tax_pre" |
"tax_loss" |
"loss" |
"third" |
"third_quarter" |
|
"quarter_sale" |
"sale_increas" |
"increas" |
"increas_by" |
"by" |
|
"by_percentsign" |
"percentsign" |
"percentsign_oper" |
"oper" |
"oper_by" |
|
"oper_rose" |
"rose" |
"rose_correspond" |
"correspond" |
"correspond_period" |
|
"period_repres" |
"repres" |
"repres_percentsign" |
"percentsign_sale" |
"oper_total" |
|
"total" |
"total_up" |
"up" |
"up_repres" |
"finnish" |
|
"finnish_talentum" |
"talentum" |
"talentum_report" |
"report" |
"report_oper" |
|
"oper_increas" |
"increas_sale" |
"sale_total" |
"cloth" |
"cloth_retail" |
|
"retail" |
"retail_chain" |
"chain" |
"chain_sepp" |
"sepp" |
|
"sepp_ls" |
"ls" |
"ls_sale" |
"consolid" |
"consolid_sale" |
|
"incres_percentsign" |
"percentsign_reach" |
"reach" |
"reach_while" |
"while_oper" |
|
"oper_amount" |
"amount" |
"amount_compar" |
"compar" |
"compar_loss" |
|
"loss_prior" |
"prior" |
"prior_period" |
"foundri" |
"foundri_divis" |
|
"divis" |
"divis_report" |
"report_sale" |
"percentsign_correspond" |
"period_sale" |
|
"sale_machin" |
"machin" |
"machin_shop" |
"shop" |
"shop_divis" |
Пример 6. Расчет и интерпретация показателей частоты слов.
Ученые по данным Джек и Джилл используют финансовые текстовые данные для разработки индикаторов настроений, позволяющих прогнозировать будущие изменения цен на акции.
Они собрали мешок слов из исследуемого текстового корпуса и получили следующие таблицы показателей частоты слов.
|
SentenceNo |
TotalWordsInSentence |
Word |
TotalWordCount |
WordCountInSentence |
SentenceCountWithWord |
|---|---|---|---|---|---|
|
< int > |
< int > |
< chr > |
< int > |
< int > |
< int > |
|
624 |
34 |
A |
873 |
6 |
687 |
|
701 |
39 |
the |
2397 |
6 |
1453 |
|
1826 |
34 |
A |
873 |
6 |
687 |
|
1963 |
39 |
the |
2397 |
6 |
1453 |
|
128 |
30 |
of |
1491 |
5 |
984 |
|
223 |
37 |
the |
2397 |
5 |
1453 |
|
SentenceNo |
TotalWordsInSentence |
Word |
TotalWordCount |
WordCountInSentence |
SentenceCountWithWord |
|---|---|---|---|---|---|
|
< int > |
< int > |
< chr > |
< int > |
< int > |
< int > |
|
28 |
7 |
risen |
3 |
1 |
3 |
|
830 |
7 |
diminish |
2 |
1 |
2 |
|
1368 |
9 |
great |
4 |
1 |
4 |
|
1848 |
8 |
injuri |
1 |
1 |
1 |
|
1912 |
7 |
cheaper |
1 |
1 |
1 |
|
1952 |
6 |
argument |
1 |
1 |
1 |
- Определите и интерпретируйте частоту слов (TF) на уровне коллекции и на уровне предложения для слова (токена) «a» в предложении 1,826 из Таблицы 1, а также для токена «great» в предложении 1,368 из Таблицы 2.
- Определите и интерпретируйте показатель TF-IDF для слова «a» в предложении 1,826 из Таблицы 1, а также для токена «great» в предложении 1,368 из Таблицы 2.
Решение для части 1:
TF на уровне коллекции рассчитывается с использованием Формулы 10:
TF (уровень коллекции) =
TotalWordCount / Общее количество слов в коллекции
Для токена «a» в предложении 1,826 (Таблица 1) TF на уровне коллекции составляет 873/44,151 = 0.019773 или 1.977%.
Для токена «great» в предложении 1,368 (Таблица 2), TF на уровне коллекции составляет 4/44,151 = 0.000091 или 0.009%.
TF на уровне коллекция является процентным индикатором частоты, с которой токен встречается во всей коллекции текстов (здесь, 44,151).
Это полезно для выявления выбросов слов: токены с самыми высокими значениями TF в основном являются стоп-словами, которые не способствуют определению настроений, встроенных в текст (например, «a»), а токены с самыми низкими значениями TF являются в основном именами собственными или редкими терминами, которые также не важны для анализа значения текста.
И наоборот, токены со средними значениями TF потенциально несут в себе важную информацию, полезную для определения настроений, встроенных в текст.
TF на уровне предложения рассчитывается с использованием Формулы 11:
TF (уровень предложения) =
WordCountInSentence / TotalWordsInSentence
Для токена «a» в предложении 1,826, TF на уровне предложения составляет
6/34 = 0.176471 или 17.647%.
Для токена «great» в предложении 1,368, TF на уровне предложения составляет
1/9 = 0.111111 или 11.111%.
TF на уровне предложения является процентным индикатором частоты, с которой токен встречается в конкретном предложении.
Следовательно, этот показатель полезен для понимания важности конкретного токена в данном предложении.
Решение для части 2:
Для расчета TF-IDF, помимо TF на уровне предложения, также требуются показатели частота документов (DF) и обратная частота документов (IDF).
DF - это количество документов (то есть предложений), которые содержат данное слово, разделенное на общее количество предложений в корпусе (здесь 2,180).
DF рассчитывается с использованием Формулы 12:
DF = SentenceCountWithWord / Общее количество предложений
Для токена «a» в предложении 1,826, DF составляет
687/2,180 = 0.315138 или 31.514%.
Для токена «great» в предложении 1,368, DF составляет
4/2,180 = 0.001835 или 0.184%.
Частота документов важна, поскольку токены, которые часто встречаются в предложениях (такие как «a»), не несут полезной информации в каждом предложении.
Однако, токены, которые реже встречаются в предложениях (такие как «great»), могут нести в себе полезную информацию.
IDF является относительным показателем того, насколько важен термин для всего корпуса (то есть, для коллекции текстов/предложений).
IDF рассчитывается с помощью Формулы 13:
IDF = log(1/DF).
Для токена «a» в предложении 1,826, IDF равен
log(1/0.315138) = 1.154746.
Для токена «great» в предложении 1,368, IDF равен
log(1/0.001835) = 6.300786.
Теперь, используя TF и IDF, можно рассчитать показатель TF-IDF с помощью Формулы 14:
TF-IDF = TF \(\times\) IDF
Для токена «a» в предложении 1,826, показатель
TF-IDF = 0.176471 \(\times\) 1.154746 = 0.203779 или 20.378%.
Для токена «great» в предложении 1,368, показатель
TF-IDF = 0.111111 \(\times\) 6.300786 = 0.700087 или 70.009%.
Поскольку TF-IDF объединяет TF на уровне предложения с IDF на уровне всего корпуса, это показатель обеспечивает полное представление значения каждого слова.
Высокое значение TF-IDF указывает на то, что слово появляется много раз в небольшом количестве документов, что означает важный, но уникальный термин в предложении (например, «great»).
Низкое значение TF-IDF указывает на токены, которые появляются в большинстве предложений и не являются значимыми (например, «a»).
Значения TF-IDF полезны для выявления ключевых терминов в документе, чтобы использовать их в качестве признаков для обучения модели машинного обучения.