CFA - Этапы проекта анализа данных: финансовое прогнозирование с помощью больших данных
Рассмотрим пошаговый процесс реализации проекта финансового прогнозирования с использованием больших данных, - в рамках изучения количественных методов по программе CFA (Уровень II).
В эпоху больших данных фирмы относятся к данным так же, как к важным активам. Тем не менее, эффективная аналитика больших данных имеет решающее значение для соответствующей монетизации данных.
Возьмем финансовое прогнозирование в качестве области применения больших данных.
Многочисленные задачи финансового прогнозирования могут извлечь выгоду из моделей, созданных с использованием методов машинного обучения.
Одним из распространенных примеров является прогнозирование того, будут ли цены на акции (для отдельных акций или портфеля) повышаться или снижаться в какой-либо конкретный момент в будущем.
Традиционно финансовое прогнозирование основывалось на различных финансовых и бухгалтерских числах, соотношениях и показателях в сочетании со статистическими или математическими моделями.
Сравнительно недавно для этого стали широко использовать модели машинного обучения.
Однако, благодаря распространению текстовых больших данных (например, новостных статей, финансовых интернет-форумов, социальных сетей) такие неструктурированные данные стали быстрее предлагать идеи (как в режиме реального времени) и обрели повышенную прогнозирующую силу.
Текстовые большие данные предоставляют несколько ценных типов информации, включая темы и настроения.
Темы (topics) - это то, что люди обсуждают (например, фирма, отрасль, конкретное событие).
Настроения (sentiment) - это то, как люди относятся к тому, что они обсуждают. Например, они могут выразить положительные, негативные или нейтральные взгляды (то есть настроения) на тему обсуждения.
Одно исследование, проведенное в Соединенных Штатах, показало, что положительные настроения в Твиттере могут предсказать тенденцию изменения индекса Доу-Джонса на трехдневный срок с почти 87% точностью.
Получение таких выводов требует, чтобы традиционные данные были дополнены текстовыми большими данными.
Как показано в Иллюстрации 1, включение больших данных имеет прямые последствия для построения модели машинного обучения, а также для финансового прогнозирования и анализа.
Начнем с верхней части Иллюстрации 1, которая показывает традиционные шаги построения модели машинного обучения с включением в нее структурированных данных:
1. Концептуализация задачи моделирования (conceptualization). Этот важный первый шаг определяет, какими должны быть выходные данные модели (например, будет ли цена акции расти / снижаться через неделю), как будет использоваться эта модель, а также кем и как будет внедряться модель в существующие или новые бизнес-процессы.
2. Сбор данных (data collection). Данные, традиционно используемые для финансовых задач, представляют собой в основном числовые данные, полученные из внутренних и внешних источников.
Такие данные, как правило, уже представлены в структурированном табличном формате, где столбцы - это признаки, а ряды - экземпляры и каждая ячейка представляет определенное значение.
3. Подготовка и первичная обработка данных (data preparation, data wrangling). Этот шаг включает очистку и предварительную обработку сырых данных.
Очистка может включать заполнение пропущенных значений, исправление значений вне диапазона и тому подобное.
Предварительная обработка может включать извлечение, агрегирование, фильтрацию и выбор соответствующих столбцов данных.
4. Исследование данных (data exploration). Этот шаг охватывает исследовательский анализ данных, выбор признаков и разработку признаков.
5. Обучение модели (model training). Этот шаг включает в себя выбор соответствующего метода (или методов) машинного обучения, оценку эффективности обученной модели и настройку модели соответствующим образом.
Обратите внимание, что эти шаги являются итеративными, потому что построение модели является итеративным процессом. Знания, полученные от одной итерации, могут информировать о пересмотре концепции (т.е. концептуализации на Этапе 1) на следующей итерации.
В отличие от структурированных источников данных, текстовые большие данные, полученные из новостных статей в Интернете, социальных сетей, внутренних / внешних документов (таких как публичная финансовая отчетность) и других открытых источников данных, - не структурированы.
Этапы построения текстовой модели машинного обучения, используемые для неструктурированных источников больших данных, показаны в нижней части Иллюстрации 1.
Они отличаются от тех, которые используются для традиционных источников данных и обычно предназначены для создания структурированной выходной информации.
Различия в этапах между текстовой моделью и традиционной моделью объясняются характеристиками больших данных: объем, скорость, разнообразие и достоверность.
В этом чтении мы в основном фокусируемся на измерениях разнообразия и достоверности текстовых больших данных.
Основные отличия этапов построения текстовой модели машинного обучения выражены в первых четырех этапах:
1. Формулировка текстовой задачи (formulation). Аналитики начинают с определения того, как сформулировать задачу классификации текста, точно определить входы и выходы модели.
Возможно, мы заинтересованы в вычислении показателей настроений (структурированный выход) из текста (неструктурированный вход). Аналитики также должны решить, как будет использоваться классификационный выход текстовой модели машинного обучения.
2. Курирование текстовых данных (curation). Этот шаг включает в себя сбор соответствующих внешних текстовых данных через веб-сервисы или программы сбора данных из интернета, которые извлекают необработанный контент из первичных источников, обычно веб-страниц.
Дополнение текстовых данных высококачественной, надежной разметкой (обозначающей целевые переменные) также может потребоваться для контролируемого обучения и оценки эффективности модели.
Например, эксперты могут добавить разметку, показывающую, является ли данная экспертная оценка акций медвежьей или бычьей.
3. Подготовка и первичная обработка текста (preparation, wrangling).
Этот шаг включает важные задачи очистки и предварительной обработки, необходимые для преобразования потоков неструктурированных текстовых данных в формат, который можно использовать в традиционных методах моделирования, работающих со структурированными входами.
4. Исследование текста (exploration). Этот шаг охватывает визуализацию текста с помощью таких методов, как облака слов, а также выбор и разработку текстовых признаков.
Полученный выход (например, прогноз настроений) можно комбинировать с другими структурированными переменными или использовать напрямую для прогнозирования и/или анализа.
Далее мы опишем два ключевых шага построения модели, изображенные в Иллюстрации 1, которые обычно отличаются при использовании структурированных данных и текстовых больших данных:
- подготовка и первичная обработка данных / текста, а также
- исследование данных / текста.
Затем мы обсудим обучение модели. Наконец, мы сфокусируемся на применении этих шагов в учебном кейсе, где показаны классификация и прогнозирование рыночных настроений с помощью финансовых текстов.
Иллюстрация 1. Построение модели финансового прогнозирования с использованием больших данных: структурированные (традиционные) в сравнении с неструктурированными (текст).
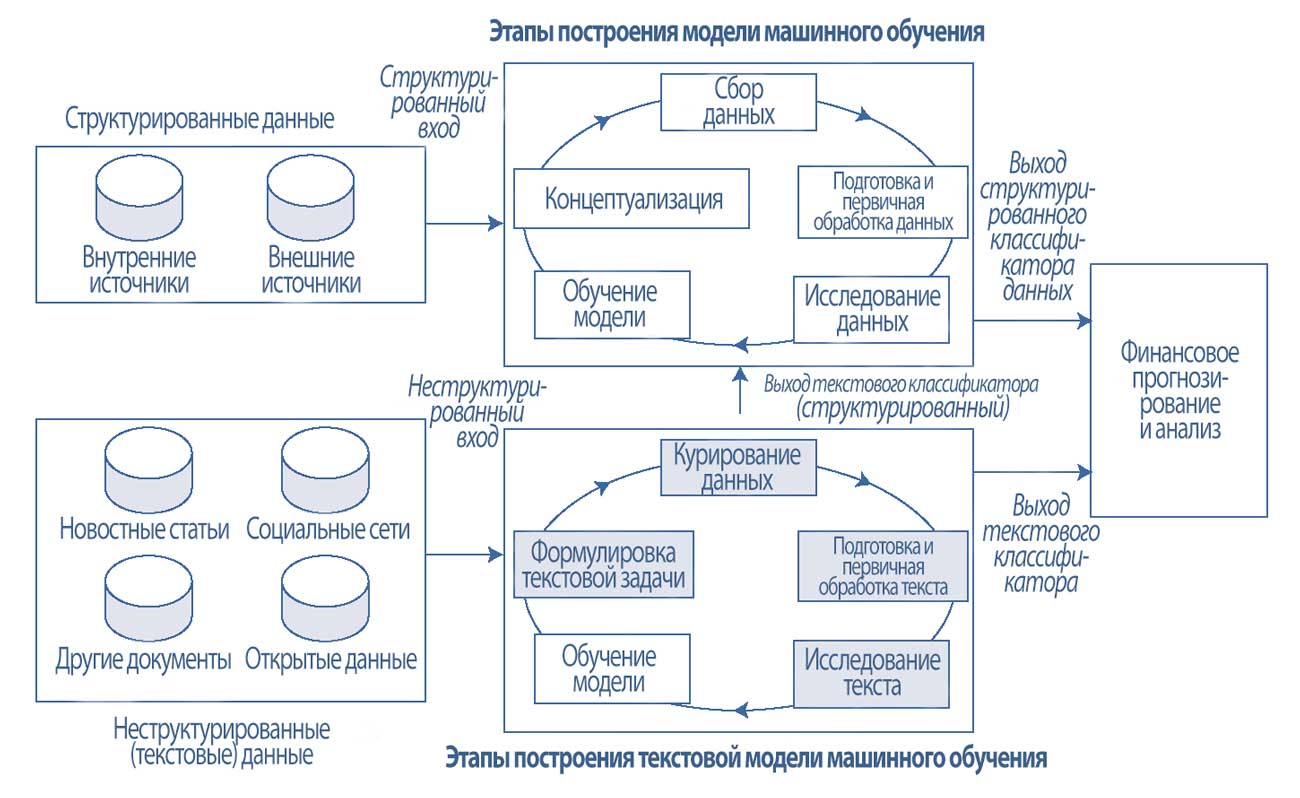
Пример 1. Этапы построения модели машинного обучения.
Компания LendALot Corporation - кредитор сегмента B2C (т.е. розничный кредитор), который традиционно отдает на аутсорсинг оценку кредитоспособности потенциальных клиентов.
Учитывая недавние достижения в области машинного обучения (ML), которые выходят за рамки традиционной оценки «истории погашения» и «способности погасить долг», LendALot хотела бы разработать внутренний кредитный скоринг на основе ML, чтобы улучшить оценку риска заемщика и дифференцировать себя на рынке кредитования B2C.
LendALot хотела бы следовать поэтапному подходу, начав с традиционных (структурированных) источников данных, а затем включая в модель текстовые (неструктурированные) источники больших данных.
Компания попросила Пола Вонга возглавить новую аналитическую команду, которой поручили разработать модель оценки кредитоспособности на основе ML.
В контексте машинного обучения, использующего структурированные источники данных, ответьте на следующие вопросы.
1. Сформулируйте и объясните решения, которые Вонг должен будет принять на каждом из этапов:
- A. Концептуализация задачи моделирования.
- B. Сбор данных.
- C. Подготовка и первичная обработка данных.
- D. Исследование данных.
- E. Обучение модели.
На более позднем этапе проекта LendALot пытается улучшить свои процессы кредитного скоринга путем включения в него текстовых данных.
Вонг говорит своей команде: «Расширьте модель оценки кредитоспособности, включив в нее идеи из произвольного текста, предоставленного потенциальными заемщиками в формах заявок на выдачу кредита».
2. Определите этап процесса, о котором говорит Вонг.
3. Укажите две потенциальные потребности команды LendALot в отношении курирования текста.
4. Укажите две потенциальные потребности команды LendALot в отношении подготовки и предварительной обработки текста.
Решение для части 1:
A. На этапе концептуализации Вонг должен будет решить, каким будет выход модели ML (например, бинарная классификация кредитоспособности), как будет использоваться модель, а также кем и как модель будет включена в бизнес-процессы LendALot.
B. На этапе сбора данных Ван должен решить, какие данные (внутренние, внешние или оба типа) нужно использовать для кредитного скоринга.
C. На этапе подготовки и первичной обработки данных Вонгу необходимо будет определить потребности в очистке и предварительной обработке данных.
Очищение может повлечь за собой заполнение пропущенных значений, корректировку недопустимых значений, и т.д. Предварительная обработка может включать извлечение, агрегирование, фильтрацию и выбор соответствующих столбцов данных.
D. На этапе исследования данных Вонг должен будет решить, какие исследовательские методы анализа данных подходят, какие признаки использовать для создания модели кредитного скоринга, а также какие признаки потребуется разработать.
E. На этапе обучения модели Вонг должен решить, какой алгоритм ML использовать. Поскольку предполагается, что доступны размеченные обучающие данные, следует выбирать алгоритмы контролируемого машинного обучения.
Следует решить, как оценивать подгонку модели, а также как осуществлять валидацию и настройку модели.
Решение для части 2:
Заявление Вонга относится к первоначальному этапу формулировки текстовой задачи.
Решение для части 3:
При курировании текста команда будет использовать внутренние данные (из заявок на выдачу кредитов).
Им нужно будет убедиться, что поля текстовых комментариев в заявках были правильно реализованы. Если эти поля не обязательны, они должны убедиться, что имеется достаточно заполненных полей для анализа.
Решение для части 4:
При подготовке и первичной обработке текста команде необходимо будет выполнить задачи очистки и предварительной обработки текста.
Эти две задачи необходимы для преобразования неструктурированного потока данных в структурированные значения, пригодные для использования в традиционных методах моделирования.