CFA - Исследование неструктурированных текстовых данных
Рассмотрим цели, методы и примеры исследования неструктурированных текстовых данных, используемых в проектах больших данных машинного обучения, - в рамках изучения количественных методов по программе CFA (Уровень II).
Исследовательский анализ текстовых данных.
Как и в случае со структурированными данными, для дальнейшего исследовательского анализа важно получить представление о существующих закономерностях в неструктурированных данных.
Аналитика текста имеет различные применения. Наиболее распространенными применениями являются классификация текста, моделирование тем, обнаружение мошенничества и анализ настроений.
Классификация текста (text classification) использует алгоритмы контролируемого машинного обучения для классификации текстов по разным классам.
Моделирование тем (topic modeling) использует методы неконтролируемого машинного обучения для группировки текстов из набора данных в тематические кластеры.
Анализ настроений (sentiment analysis) прогнозирует настроения (отрицательные, нейтральные или положительные) текстов из набора данных с использованием подходов контролируемого и неконтролируемого машинного обучения.
Различные статистические показатели используются для изучения, обобщения и анализа текстовых данных. Текстовые данные включают набор текстов (также известный как корпус [corpus]), которые являются последовательностями токенов.
Полезно выполнить исследовательский анализ (EDA, exploratory data analysis) текстовых данных путем вычисления на основе токенов таких базовых показателей текста, как частота слов.
Частота слов или частота терминов (TF, term frequency) - это коэффициент, отражающий отношение количества раз, которое данный токен встречается во всех текстах набора данных к общему количеству токенов в наборе данных (например, ассоциации слов, средняя длина слова и предложения, а также количество слов и слогов).
Статистические показатели текста раскрывают закономерности в совместном появлении слов в тексте. Существует множество применений текстовой аналитики, и необходимые статистические показатели текста варьируются в зависимости от контекста применения.
Моделирование тем (topic modeling) - это применение текстовых данных, при котором наиболее информативные слова идентифицируются путем расчета TF для каждого слова.
Например, слово «футбол» может быть информативным для темы «спорт».
Слова с высокими значениями TF устраняются, поскольку они, вероятно, окажутся стоп-словами или другими общими словарными словами, что делает полученный мешок слов компактным и с большей вероятностью имеющим отношение к тематикам текстов.
При анализе настроений и классификации текста показатель хи-квадрат, показывающий ассоциации слов, может быть полезен для понимания значимого появления слов в негативных и положительных предложениях в тексте или в разных документах. Далее мы дополнительно объясним применение показателя хи-квадрат.
Такой исследовательский анализ играет жизненно важную роль в выполнении этапа выбора признаков.
Статистические показатели текста можно сделать визуально понятными при использовании способов визуализации, описанных в разделе об исследовании структурированных данных.
Например, столбчатые диаграммы можно использовать для подсчета и вычисления частот слов. Облака слов являются распространенным способом визуализациями при работе с текстовыми данными, поскольку они выводят наиболее информативные слова и их значения TF.
Наиболее часто встречающиеся слова в наборе данных можно показать с помощью различного размера шрифта, а цвет обычно используется для добавления в облако слов большего количества измерений, таких как частота и длина слов.
В Иллюстрации 17 показано облако слов, построенное на основе выборки из набора данных, состоящего из финансовых новостей, после обработки текста. Функции построения облака слов доступны в популярных языках программирования.
Подробная демонстрация исследовательского анализа текстовых данных будет представлена далее, в разделе, посвященном работе с реальными текстовыми данными в проекте финансового прогнозирования.
Иллюстрация 17. Облако слов на основе выборки финансовых новостей.
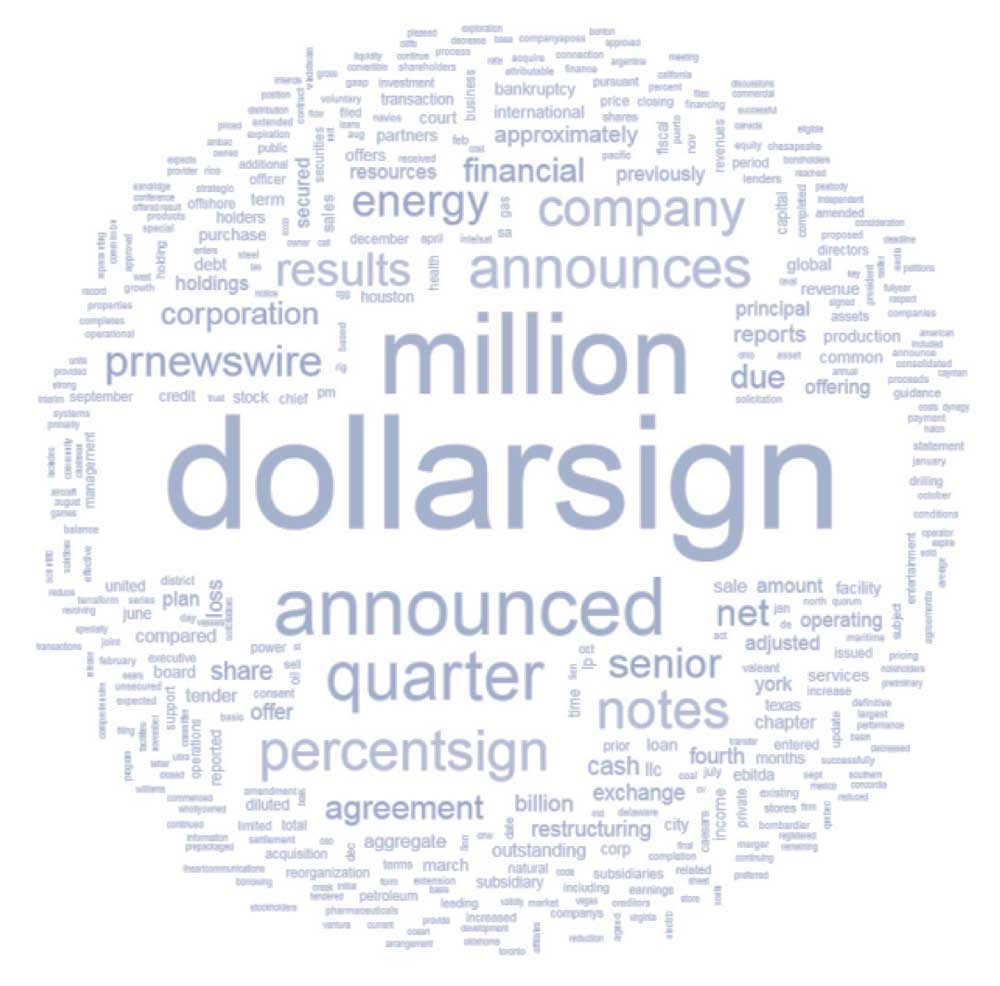
Облако слов на основе выборки финансовых новостей.
Выбор признаков.
Для текстовых данных выбор признаков включает в себя выбор подмножества слов или токенов, встречающихся в наборе данных. Токены служат признаками для обучения модели машинного обучения.
Выбор признаков в текстовых данных эффективно уменьшает размер словаря или мешка слов. Это помогает модели быть более эффективной и менее сложной.
Другое преимущество - устранение шумных признаков из набора данных. Шумные признаки - это токены, которые не способствуют обучению модели и фактически могут снижать точность модели машинного обучения.
Шумные признаки являются наиболее частыми и наиболее редкими токенами в наборе данных.
С одной стороны, шумные признаки могут быть стоп-словами, которые обычно часто встречаются во всех текстах набора данных.
С другой стороны, шумные признаки могут быть редкими словами, которые присутствуют в тексте только в нескольких случаях.
Классификация текста включает в себя разделение текстовых документов на заданные классы (класс - это категория; например, «релевантные» и «нерелевантные» текстовые документы или «медвежьи» и «бычьи» котировки акций).
- Частые токены усложняют для модели принятие решения в отношении разных текстов, поскольку слова присутствуют во всех текстах, что является примером недостаточного обучения модели.
- Редкие токены вводят в заблуждение модель при классификации текстов, содержащих редкие слова, что является примером переобучения модели.
Выявление и удаление шумных признаков очень важно для классификации текста.
Общие методы выбора признаков в текстовых данных следующие:
1. Показатели частот могут использоваться для сокращения словаря с целью удаления шумных признаков путем фильтрации токенов с очень высокими и низкими значениями TF во всех текстах.
Частота документа (DF, document frequency) - это еще один показатель частоты, который помогает устранить шумные признаки, которые не содержат конкретной информации о классе текста и присутствуют во всех текстах.
DF токена определяется как количество документов (текстов), которые содержат соответствующий токен, разделенное на общее количество документов. Это самый простой метод выбора признаков, который часто хорошо работает, если данные включают много тысяч токенов.
2. Тест (критерий) хи-квадрат может быть полезен для выбора признаков в текстовых данных. Тест хи-квадрат применяется для проверки независимости двух событий: возникновение токена и возникновение класса.
Тест оценивает токены по их полезности для каждого класса в задачах классификации текста.
Токены с самыми высокими значениями критерия хи-квадрат чаще встречаются в текстах, связанных с конкретным классом, и, следовательно, могут быть выбраны для использования в качестве признаков для обучения модели из-за их более высокого отличительного потенциала.
3. Полное количество информации (MI, mutual information) - это показатель, который оценивает, сколько информации предоставляет токен для класса текстов.
Значение MI будет равно 0, если распределение токена во всех классах текста одинаково.
Значение MI стремится к 1, если токены встречаются более часто только в одном конкретном классе текста.
В Иллюстрации 18 показано простое изображение некоторых токенов с высокими показателями MI для соответствующих классов текста.
Обратите внимание, что токены (или признаки) с самыми высокими значениями MI тесно связаны с названием соответствующего класса текста.
Иллюстрация 18. Токены со значениями полного количества информации (MI) для двух заданных классов текста.
|
Спорт |
Политика |
||
|---|---|---|---|
|
Токен |
Значение MI |
Токен |
Значение MI |
|
soccer |
0.0781 |
election |
0.0612 |
|
cup |
0.0525 |
president |
0.0511 |
|
match |
0.0456 |
polls |
0.0341 |
|
play |
0.0387 |
vote |
0.0288 |
|
game |
0.0299 |
party |
0.0202 |
|
team |
0.0265 |
candidate |
0.0201 |
|
win |
0.0189 |
campaign |
0.0201 |
Разработка признаков.
Как и в случае структурированных данных, разработка признаков может значительно улучшить обучение модели и является сочетанием искусства и науки.
Ниже приведены некоторые методы для разработки признаков, которые могут пересекаться с методами обработки текста.
1. Числа: при обработке текста числа преобразуются в токены, такие как «/number/».
Тем не менее, числа могут быть разной длины и представлять различные виды чисел, поэтому может быть полезно преобразовать разные числа в разные токены.
Например, цифры с четырьмя цифрами могут указывать на годы, а числа со множеством цифр могут быть идентификационным номером.
Четырехзначные числа можно заменить на «/number4/», 10-значные числа на «/number10/» и т.д.
2. N-граммы: сочетания из нескольких слов, которые особенно характерны для текста, можно идентифицировать, а соединяющий их символ остается нетронутым.
Например, «market» (рынок) - это общее слово, которое может указывать на многие предметы или классы; а слова «stock market» (фондовый рынок) используются в конкретном контексте и могут быть полезны, чтобы отличить тексты общей тематики от текстов, связанных с финансами.
Здесь может быть полезна биграмма, так как она рассматривает два соседних слова как один токен (например, stock_market).
3. Распознавание именованных сущностей (NER, name entity recognition): NER - обширная процедура, доступная в качестве библиотеки или пакета во многих языках программирования.
Алгоритм распознавания именованных сущностей анализирует отдельные токены и окружающую их семантику, обращаясь к своему словарю, чтобы присвоить токену класс объекта в качестве метки (тега).
В Иллюстрации 19 показаны NER-теги для текста «CFA Institute was formed in 1947 and is headquartered in Virginia».
Дополнительные классы, например, MONEY, TIME и PERCENT отсутствуют в этом примере текста.
NER-теги, когда это применимо, могут использоваться в качестве признаков для обучения модели, чтобы улучшить ее эффективность. NER-теги также могут помочь выявить важнейшие токены, для которых нельзя применять такие операции, как преобразование символов в нижний регистр и стемминг (например, здесь слово Institute относится к конкретной организации, и не является глаголом).
Такие методы делают признаки более отличительными.
Иллюстрация 19. Распознавание именованных сущностей (NER) и частей речи (POS) на примере текста.
|
Токен |
NER-тег |
POS-тег |
Описание POS-тега |
|---|---|---|---|
|
CFA |
ORGANIZATION |
NNP |
Proper noun |
|
Institute |
ORGANIZATION |
NNP |
Proper noun |
|
was |
VBD |
Verb, past tense |
|
|
formed |
VBN |
Verb, past participle |
|
|
in |
IN |
Preposition |
|
|
1947 |
DATE |
CD |
Cardinal number |
|
and |
CC |
Coordinating conjunction |
|
|
is |
VBZ |
Verb, 3rd person singular present |
|
|
headquartered |
VBN |
Verb, past participle |
|
|
in |
IN |
Preposition |
|
|
Virginia |
LOCATION |
NNP |
Proper noun |
4. Части речи (POS, parts of speech): аналогично NER, части речи используют языковую структуру и словари, чтобы отметить каждый токен в тексте тегом соответствующей части речи.
Распространенными POS-тегами являются существительное (noun), глагол (verb), прилагательное (adjective) и имя собственное (proper noun). В Иллюстрации 19 показаны POS-теги и их описания на примере текста.
POS-теги могут использоваться в качестве признаков для обучения модели и для определения количества токенов, которые принадлежат каждому тегу POS. Если данный текст содержит много имен собственных, это означает, что он может быть связан с людьми и организациями и может относиться к бизнес-тематике.
POS-теги могут быть полезны для разделения глаголов и существительных в текстовой аналитике. Например, слово «market» может быть глаголом в выражении «to market ...» или существительным в выражении «in the market».
Учет различий таких токенов может помочь дополнительно прояснить значение текста.
Использование слова «market» в качестве глагола может указывать на то, что текст относится к теме маркетинга и может быть посвящен маркетингу продукта или услуги.
Использование слова «market» в качестве существительного может означать, что текст относится к товарному или фондовому рынку и может быть посвящен торговле акциями.
Также при разметке POS-тегами такие составные существительные, как «CFA Institute», можно рассматривать как один токен. Разметку POS-тегами можно выполнить с помощью библиотек или пакетов языков программирования.
Целью разработки признаков является поддержание семантической сущности текста, при упрощении и преобразовании его в структурированные данные для машинного обучения.
Пример (4) исследования данных.
Аналитическая команда Пола Вонга из LendALot Corporation завершила свою первоначальную подготовку и первичную обработку данных, связанную с их работой над моделью классификации клиентов по уровню кредитоспособности.
В качестве следующего шага Вонг попросил одного из членов команды, Эрика Кима, изучить доступные структурированные источники данных, чтобы понять, какие виды исследовательского анализа данных имеет смысл применять.
Киму было поручено сообщать команде о закономерностях и тенденциях в данных, а также о том, какие переменные кажутся интересными.
Эти сведения могут повлиять на решения команды относительно обучения модели, а также на то, следует ли включать текстовые большие данные во входы модели.
Используйте следующую выборку столбцов и рядов, которые Ким использовал для своей проверки, чтобы ответить на следующие вопросы.
|
1 |
ID |
Результат погашения кредита |
Доход ($) |
Сумма кредита ($) |
Кредитный балл |
Тип кредита |
Произвольные ответы на просьбу «Объяснить кредитный балл» (выдержки из полного текста) |
|---|---|---|---|---|---|---|---|
|
2 |
1 |
No Default |
34,000 |
10,000 |
685 |
Mortgage |
I am embarrassed that my score is below 700, but it was due to mitigating circumstances. I have developed a plan to improve my score. |
|
3 |
2 |
No Default |
63,050 |
49,000 |
770 |
Student Loan |
I have a good credit score and am constantly looking to further improve it... |
|
4 |
3 |
Defaulted |
20,565 |
35,000 |
730 |
Student Loan |
I think I have great credit. I don't think there are any issues. Having to provide a written response to these questions is kind of annoying. |
|
5 |
4 |
No Default |
50,021 |
10,000 |
664 |
Mortgage |
I have a decent credit score. I regret not being as responsible in the past but feel I have worked hard to improve my score recently. |
|
6 |
5 |
Defaulted |
100,350 |
129,000 |
705 |
Car Loan |
Honestly, my score probably would have been higher if I had worked harder. But it is probably good enough. |
|
7 |
6 |
No Default |
800,000 |
300,000 |
800 |
Boat Loan |
I have worked hard to maintain a good credit rating. I am very responsible. I maintain a payment schedule and always stick to the payment plan. |
- Оцените, могут ли методы визуализации данных, такие как гистограммы, графики размаха и диаграммы рассеяния, использоваться для исследовательского анализа данных.
- Укажите способ визуализации, который подходит для изучения произвольных ответов.
- Опишите, как можно использовать методы ранжирования для выбора потенциально интересных для команды признаков.
- Приведите примеры биграмм из текста произвольных ответов, которые можно использовать для определения результата погашения кредита.
Решение для части 1:
Представленные данные включают структурированные признаки (ID, Результат погашения кредита, Доход, Сумма кредита, Кредитный балл) и неструктурированные данные.
Гистограммы, графики размаха и диаграммы рассеяния являются методами визуализации, подходящими для признаков структурированных данных.
Ким может использовать гистограммы и графики размаха, чтобы увидеть, как распределяются доход, сумма кредита и кредитный балл.
Более того, эти графики можно построить для всех исторических наблюдений о заимствованиях из набора данных, а также для сопоставления дефолтных и не дефолтных кредитов.
Графики рассеяния для дохода по отношению к сумме кредита; дохода по отношению к кредитному баллу; а также для суммы кредита по отношению к кредитному рейтингу, могут пролить свет на взаимосвязь между потенциально важными непрерывными переменными.
Решение для части 2:
Для текста в поле произвольного ответа следует использовать облака слов в качестве отправной точки для исследовательского анализа. Облако слов позволяет быстро оценить наиболее часто встречающиеся слова (то есть частоты слов).
Хотя некоторые очевидные слова (например, «credit» и «score») могут быть ценными, другие часто встречающиеся слова (например, «worked», «hard», «probably», «embarrassed», «regret», «good», «decent» и «great») потенциально подходят для прогнозирования кредитоспособности.
Решение для части 3:
Ким может использовать методы выбора признаков для ранжирования всех признаков. Поскольку в этом случае интересующая целевая переменная (Результат погашения кредита) дискретна, такие методы, как хи-квадрат и MI, хорошо подойдут.
Это одномерные методы, которые позволяют оценить переменные признаков по отдельности.
В дополнение к структурированным признакам, эти методы одномерного ранжирования также можно применить к признакам, связанным с подсчетом слов, таким как частота слов и частота документов, которые рассчитываются на основе частоты появления слов в тексте.
Такие часто встречающиеся слова (например, «worked» и «hard») можно идентифицировать с помощью облака слов.
Решение для части 4:
Биграммы «credit_score» и «work_hard», полученные из текста произвольных ответов, потенциально позволяют определить результат погашения кредитов.