CFA - Настройка модели машинного обучения
Рассмотрим настройку модели на этапе обучения модели машинного обучения в проекте больших данных, - в рамках изучения количественных методов по программе CFA (Уровень II).
Как только проведена оценка эффективности модели, необходимо принять определенные решения и выполнить определенные действия на основе полученных результатов, чтобы повысить эффективность модели.
Если ошибка прогнозирования при использовании обучающих данных высока, модель является недостаточно обученной.
Если ошибка прогнозирования при кросс-валидации (CV) значительно выше, чем при использовании обучающих данных, модель является переобученной.
Подгонка (обучение) модели имеет два типа ошибки: смещение и дисперсия. Ошибка смещения (bias error) связана с недостаточным обучением, а ошибка дисперсии (variance error) связана с переобучением.
Ошибка смещения высока, когда модель чрезмерно упрощена и недостаточно учится на паттернах обучающих данных.
Ошибка дисперсии высока, когда модель чрезмерно сложна и запоминает так много обучающих данных, что, вероятно, будет плохо работать на новых данных.
Невозможно полностью устранить оба типа ошибок. Тем не менее, обе ошибки можно свести к минимуму, поэтому общая агрегированная ошибка (ошибка смещения + ошибка дисперсии) будет минимальна.
Компромисс между ошибками смещения и дисперсии имеет решающее значение для поиска оптимального баланса, при котором модель не будет ни недостаточно обученной, ни переобученной.
- Параметры имеют решающее значение для модели и зависят от обучающих данных. Параметры подбираются на основе обучающих данных в процессе обучения модели с помощью метода оптимизации.
Примеры параметров включают коэффициенты (в регрессиях), веса (в нейросетях) и опорные векторы (для метода опорных векторов SVM). - Гиперпараметры используются для оценки параметров модели и не зависят от обучающих данных.
Примеры гиперпараметров включают член регуляризации (\(\lambda\)) в контролируемых моделях; функцию активации и количество скрытых слоев в нейросетях; количество деревьев и глубину дерева в ансамблевых методах; параметр \(k\) в методе k ближайших соседей и при кластеризации k-средних; а также порог \(p\) в логистической регрессии.
Гиперпараметры устанавливаются и настраиваются вручную.
Например, если исследователь использует модель логистической регрессии для классификации предложений из финансовых отчетов как положительные или отрицательные настроения для покупки акций, начальной точкой отсечения для обученной модели может быть p-порог 0.50 (50%).
Следовательно, любое предложение, для которого модель определяет вероятность > 50%, классифицируется как положительное настроение.
Исследователь может создать матрицу неточностей из результатов классификации (на основе набора данных кросс-валидации), чтобы определить такие показатели эффективности модели, как общая точность и оценка F1.
Затем исследователь может варьировать p-порог логистической регрессии (допустим, установив его равным 0.55 (55%), 0.60 (60%) или даже 0.65 (65%), а затем повторно запустить кросс-валидацию, создать новые матрицы неточностей на основе новых результатов классификации и сравнить показатели общей точности и оценки F1.
В конечном счете, исследователь выберет модель логистической регрессии с таким p-порогом, который дает результаты классификации, показывающие наивысшие показатели общей точности и оценки F1.
Для оценки гиперпараметров не существует общепринятой формулы.
Таким образом, настройка эвристики и такие методы, как поиск по сетке, используются для получения оптимальных значений гиперпараметров.
Поиск по сетке (grid search) - это метод систематического обучения модели машинного обучения с использованием различных комбинаций значений гиперпараметра, перекрестной валидации каждой модели и определения того, какая комбинация значений гиперпараметра обеспечивает наилучшую эффективность модели.
Модель обучается с использованием различных комбинаций значений гиперпараметра, пока не будет обнаружен оптимальный набор значений. Оптимальные значения должны привести к аналогичной эффективности модели на обучающем и кросс-валидационном (CV) наборе данных, что означает, что ошибка обучения и ошибка кросс-валидации близки.
Это гарантирует, что модель будет способна обобщать тестовые данные или новые данные и, следовательно, с меньшей вероятностью является переобученной. График ошибок обучения для каждого значения гиперпараметра (например, изменяющего сложность модели) называется кривой подгонки или обучаемости модели (fitting curve).
Кривые обучаемости обеспечивают визуальное понимание эффективности модели (для данного гиперпараметра и уровня сложности модели) на обучающих и кросс-валидационных (CV) наборах данных. Они полезны для настройки гиперпараметров.
В Иллюстрации 26 показан компромисс между ошибками смещения и дисперсии, который определяется путем построения кривой обучаемости для гиперпараметра регуляризации (\(lambda\)).
Иллюстрация 26. Кривая обучаемости для гиперпараметра регуляризации.
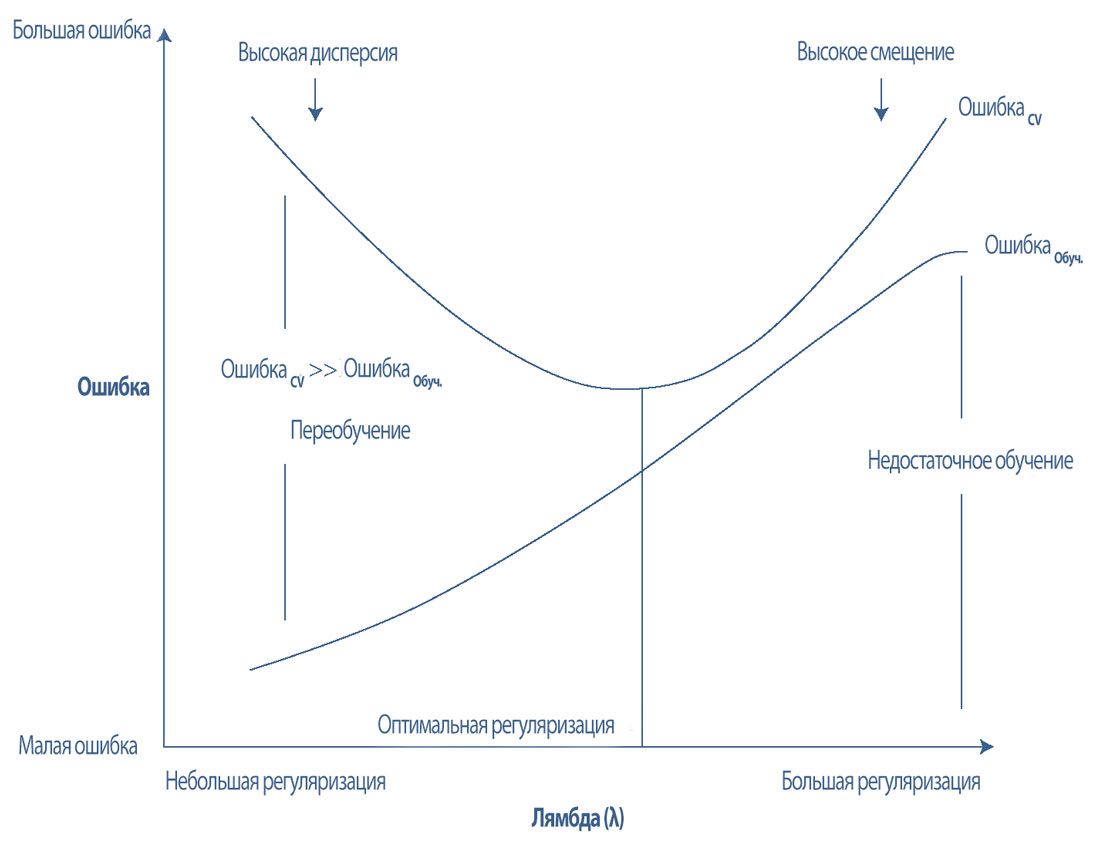
Кривая обучаемости для гиперпараметра регуляризации.
Небольшая регуляризация слабо наказывает (пенализирует) за сложность модели, что позволяет включить большинство или все признаки в модель и, следовательно, потенциально позволяет модели «запоминать» данные.
Как правило, при небольшой регуляризации или отсутствии регуляризации ошибка прогнозирования в обучающем наборе данных небольшая, в то время как ошибка прогнозирования в CV наборе данных значительно больше.
Эта разница в ошибке заключается в дисперсии. Большая ошибка дисперсии, которая обычно является результатом слишком большого количества признаков и высокой сложности модели, приводит к переобучению модели.
Когда есть большие ошибки дисперсии и низкие ошибки смещения, модель хорошо работает на обучающем наборе данных, но генерирует много FP и FN ошибок в CV наборе данных. Другими словами, модель переобучена и плохо обобщает новые данные.
Большая регуляризация чрезмерно наказывает (пенализирует) за сложность модели, что позволяет включить слишком мало признаков в модель и приводит к тому, что модель меньше учится на данных.
Модели может не хватать необходимых прогнозирующих переменных и сложности, необходимых для выявления основных закономерностей в данных. Как правило, при большой регуляризации ошибки прогнозирования в обучающем и CV наборах данных являются большими.
Большие ошибки прогнозирования в обучающем наборе данных указывают на высокое смещение, а большие ошибки смещения возникают в результате недостаточного обучения модели.
Когда есть большая ошибка смещения, модель не работает хорошо ни на обучающих, ни на CV наборах данных, потому что ей обычно не хватает важных прогнозирующих переменных.
Оптимальная регуляризация сводит к минимуму, как ошибки дисперсии, так и ошибки смещения сбалансированным образом. Она оптимально наказывает (пенализирует) за сложность модели, так что в модель включается только самые важные признаки.
Этот процесс предотвращает запоминание данных модели, позволяя модели достаточно изучить данные, чтобы различать важные закономерности.
Это приводит к схожим ошибкам прогнозирования на обучающем и CV наборах данных, которые также являются минимальными. Диапазон оптимальных значений регуляризации можно найти эвристически, используя такие методы, как поиск по сетке.
Если после настройки гиперпараметров присутствуют высокое смещение или дисперсия, может потребоваться большее количество учебных примеров (экземпляров), а также, либо уменьшение количества признаков, включенных в модель (в случае высокой дисперсии), либо увеличение (в случае высокого смещения).
Затем модель необходимо повторно обучить и повторно настроить с помощью нового обучающего набора данных.
В случае сложной модели, где большая модель состоит из подмодели или подмоделей, можно выполнить анализ верхнего предела.
Анализ верхнего предела (ceiling analysis) является систематическим процессом оценки различных компонентов, использующихся в конвейере (вычислений) построения модели. Он помогает понять, какая часть конвейера может потенциально улучшить эффективность за счет дальнейшей настройки.
Например, модели прогнозирования фондового рынка нуждаются в исторических данных с фондового рынка и, возможно, новостных статьях, связанных с акциями.
Подмодель будет извлекать соответствующую информацию из новостных статей или классифицировать настроения новостных статей. Результаты подмодели будут включены в более крупную модель в качестве признаков.
Таким образом, эффективность более крупной модели зависит от эффективности подмоделей. Анализ верхнего предела может помочь определить, какую подмодель необходимо настроить для повышения общей точности более крупной модели.