CFA - Обучение модели машинного обучения в проекте больших данных
Рассмотрим цели, шаги и методы этапа обучения модели проекта больших данных с помощью структурированных и неструктурированных данных, а также выбор метода обучения, - в рамках изучения количественных методов по программе CFA (Уровень II).
Обучение модели машинного обучения (ML) - это систематический, итеративный и рекурсивный процесс.
Количество итераций, необходимых для достижения оптимальных результатов, зависит от:
- характера задачи и входных данных и
- уровня эффективности модели, необходимого для практического применения.
Модели машинного обучения объединяют в себе несколько принципов и операций, обеспечивающих получение прогнозов. Как показано в двух последних разделах, построение типичной модели ML требует этапа подготовки и первичной обработки данных (очистки и предварительной обработки) а также этапа исследования данных (исследовательский анализ данных, выбор и разработка признаков).
Кроме того, для хорошего построения и обучения модели требуется знание области данных.
Например, знания в области управления инвестициями и торговли ценными бумагами важны при использовании финансовых данных для обучения модели, которая прогнозирует затраты на торговлю акциями. Для инженеров и экспертов ML очень важно работать совместно при построении и обучении моделей ML.
Три задачи обучения модели ML - это:
- выбор методов,
- оценка эффективности (качества) и
- настройка.
Иллюстрация 20 показывает этап обучения модели и три входящие в него задачи.
Выбор метода (method selection) - это искусство и наука принятия решения о том, какие методы машинного обучения следует включать в модель, руководствуясь при этом такими соображениями, как классификация данных, тип данных и размер данных.
Оценка эффективности или качества модели (performance evaluation) влечет за собой использование множества дополнительных методов и показателей для количественной оценки эффективности модели.
Настройка (tuning) - это процесс принятия решений и выполнения некоторых действий для повышения эффективности модели.
Эти шаги могут повторяться несколько раз, пока не будет достигнут желаемый уровень эффективности модели машинного обучения.
Хотя не существует стандартного свода правил для обучения модели ML, фундаментальное понимание специфичных обучающих данных и принципов алгоритма ML играет жизненно важную роль для хорошего обучения модели.
Иллюстрация 20. Этап обучения модели машинного обучения.

Этап обучения модели машинного обучения.
Перед обучением модели важно сформулировать задачу, определить цели, определить полезные точки данных и концептуализировать модель.
Концептуализация похожа на план на чертежной доске, который можно постоянно менять, что необходимо для инициирования процесса обучения модели.
Поскольку моделирование является итеративным процессом, в план модели вносится множество изменений и усовершенствований по мере работы над совершенствованием процесса.
Структурированные и неструктурированные данные.
Процесс обучения модели машинного обучения на основе структурированных и неструктурированных данных, как правило, такой же. Большинство моделей ML предназначены для обучения структурированным данным, поэтому неструктурированные данные на стадии подготовки данных обрабатываются и преобразуются в структурированный формат.
Систематическая обработка неструктурированных текстовых данных с представлением их в виде матрицы данных была освещена ранее.
Аналогичным образом, другие формы неструктурированных данных (помимо текстовых данных) также можно подготовить и представить в виде матрицы данных для обучения ML.
Основная идея обучения модели ML заключается в подборе системы правил на основе обучающего набора данных, которая позволит выявлять паттерны (закономерности) в данных. Другими словами, эта система правил описывает степень, в которой (или насколько хорошо) модель ML способна обобщать новые данные.
Хорошая модель означает хорошую эффективность модели при использовании новых данных вне учебного набора данных (то есть, вне выборки).
Иллюстрация 21 показывает границы принятия решений моделью при трех возможных сценариях обучения модели для задачи классификации, включающей два разных класса данных (то есть круги и треугольники).
Модель слева недостаточно обучена; она недостаточно хорошо соответствует обучающим данным, поскольку приводит к четырем ошибкам классификации (три круга и один треугольник).
Хотя модель в центре, которая генерирует S-образную линию, имеет наилучшую точность (без ошибок) для обучающих данных, она является переобученной (то есть слишком хорошо подходит к обучающим данным) и, следовательно, вряд ли будет хорошо работать в будущих тестах.
Модель справа (с одной ошибкой классификации круга) - это хорошо обученная модель (то есть она хорошо подходит к обучающим данным, но не настолько хорошо, чтобы плохо обобщать данные вне выборки).
Иллюстрация 21. Сценарии обучения моделей: недостаточное обучение, переобучение и хорошее обучение.

Сценарии обучения моделей: недостаточное обучение, переобучение и хорошее обучение.
Ошибки обучения модели вызваны несколькими факторами - основными из них являются размер набора данных и количество признаков в наборе данных.
Размер набора данных: небольшие наборы данных могут привести к недостаточному обучению модели, поскольку небольшие наборы данных часто недостаточны для обнаружения паттернов в данных. Ограниченная небольшим набором данных модель ML может не распознать важные закономерности.
Количество признаков: набор данных с небольшим количеством признаков может привести к недостаточному обучению, а набор данных с большим количеством признаков может привести к переобучению.
Как и в случае с небольшим размером набора данных, небольшое количество признаков может не иметь всех характеристик, которые объясняют связи между целевой переменной и признаками.
И наоборот, большое количество признаков может усложнить модель и потенциально исказить закономерности в данных из-за низкого числа степеней свободы, что вызывает переобучение.
Следовательно, надлежащий выбор признаков с использованием методов, описанных ранее (например, хи-квадрат, метод полного количества информации) является ключевым фактором для минимизации переобучения модели.
Разработка новых признаков обычно помогает предотвратить недостаточное обучение модели. Новые признаки при правильной разработке позволяют лучше объяснить взаимодействие признаков.
Таким образом, разработка признаков может иметь решающее значение для преодоления недостаточного обучения. Связанные с методом факторы, которые влияют на подгонку (обучение) модели, мы объясним далее, когда будет рассматривать настройку модели.
Выбор метода обучения модели.
Обучение модели ML - это целая профессия (частично искусство и частично наука); для этой задачи нет строгих руководящих принципов.
Выбор и применение метода или алгоритма является первым шагом процесса обучения. Выбор метода регулируется следующими факторами:
1. Контролируемое или неконтролируемое обучение. Обучающие и тестовые данные для обучения и тестирования контролируемой модели машинного обучения содержат основополагающую истину, известный результат (то есть целевую переменную) для каждого наблюдения в этих наборах данных.
Неконтролируемое машинное обучение - это относительно сложный процесс из-за отсутствия основополагающей истины (то есть, процесс не имеет целевой переменной).
Контролируемые модели создают структуру, которая может поддерживаться или не поддерживаться данными.
Неконтролируемые модели не создают структуру за пределами той, которая возникает из данных.
Для контролируемого обучения (с размеченными обучающими данными) типичными методами являются регрессия, ансамблевое обучение и случайный лес, метод опорных векторов (SVM) и нейронные сети.
Контролируемое обучение может использоваться, например, для прогнозирования дефолта на основе данных об эмитенте высокодоходных корпоративных облигаций.
Для неконтролируемого обучения обычными методами являются уменьшение размерности, кластеризация и обнаружение аномалий.
Например, неконтролируемое обучение будет использоваться для кластеризации финансовых учреждений в различные группы на основе их финансовых атрибутов.
2. Тип данных. Для числовых данных (например, прогнозирование цен на акции с использованием исторических значений фондового рынка) могут подойти методы дерева классификации и регрессии (CART).
Для текстовых данных (например, прогнозирование темы финансовой новостной статьи на основе заголовка статьи), используются такие методы, как линейные модели и SVM.
Для графических данных (например, идентификация объектов на спутниковых снимках, таких как танкерные суда, входящие в порт и выходящие из порта), как правило, лучше подходят нейросети и методы глубокого обучения.
Для речевых данных (например, прогнозирование финансовых настроений на основе аудиозаписей обсуждений ежеквартальных доходов) методы глубокого обучения могут предложить многообещающие результаты.
3. Размер данных. Типичный набор данных имеет две основные характеристики: количество экземпляров (то есть наблюдений) и количество признаков. Комбинация этих двух характеристик помогает определить, какой метод наиболее подходит для обучения модели.
Например, было обнаружено, что методы SVM хорошо работают с «более широкими» наборами данных, имеющими от 10,000 до 100,000 признаков и меньшее количество экземпляров.
Нейросети, наоборот, часто работают лучше с «более длинными» наборах данных, где количество экземпляров намного больше, чем количество признаков.
После выбора метода необходимо принимать определенные решения, связанные с методом (например, установить гиперпараметры). Например, эти решения включают выбор количества скрытых слоев в нейронной сети и выбор количества деревьев в ансамблевых методах.
На практике наборы данных могут быть комбинацией числовых и текстовых данных. Чтобы справиться со смешанными данными, можно объединить результаты более чем одного метода. Иногда прогнозы на основе одного метода могут быть использованы в качестве предикторов (признаков) для других методов.
Например, неструктурированные данные финансового текста могут использоваться в логистической регрессии для классификации настроений о покупке акций - как положительные или отрицательные.
Затем эта классификации настроений могут использоваться в качестве предиктора в более крупной модели, скажем, CART, которая также использует структурированные финансовые данные в качестве предикторов для выбора акций.
Наконец, можно использовать более одного метода, и результаты в сочетании с количественным или субъективным взвешиванием будут использовать преимущества каждого метода.
В случае контролируемого обучения, до начала обучения модели исходный набор данных делится на три подмножества, используемые в целях обучения и тестирования моделей.
Первое подмножество, обучающий набор, используемый для обучения модели, должен составлять приблизительно 60% исходного набора данных.
Второе подмножество, набор для перекрестной валидации (или валидационный набор), используемый для настройки и проверки модели, должен составлять приблизительно 20% от основного набора данных.
Третье подмножество - это тестовый набор для тестирования модели, который использует оставшиеся данные.
Данные делятся на подмножества с использованием метода случайной выборки, такого как метод k-кратной кросс-валидации.
Рекомендуемые пропорции разделения обычно составляют 60:20:20, как подробно описано выше; Тем не менее, это соотношение может варьироваться.
Для неконтролируемого обучения не требуется разделение из-за отсутствия размеченных обучающих данных.
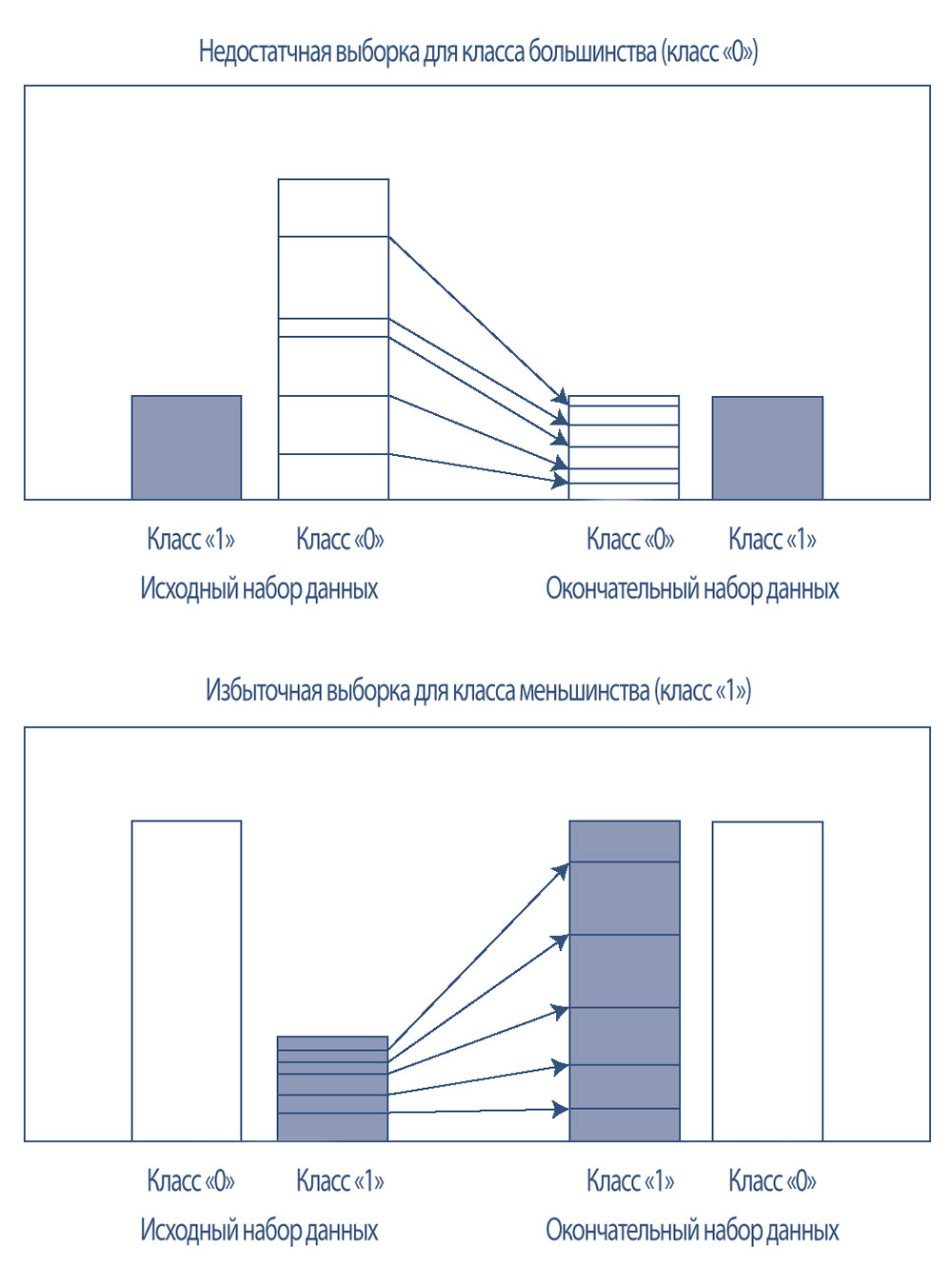
Дисбаланс класса, когда количество экземпляров для одного класса значительно больше, чем для других классов, может быть проблемой для данных, используемых в контролируемом обучении, поскольку целью метода классификации является обучение модели с высокой точностью.
В примере прогнозирования дефолта эмитентов облигаций с кредитным рейтингом в диапазоне от BB+/Ba1 до B+/B1, эмитентов, которые допустили дефолт (положительный прогноз или класс «1»), было очень мало по сравнению с эмитентами, которые не допустили дефолт (отрицательный прогноз или класс «0»).
Следовательно, наивная модель, которая просто предполагает, что ни один корпоративный эмитент не может допустить дефолт, может показывать хорошую точность, даже с учетом того, что все случаи дефолта будут неправильно классифицированы. Балансирование обучающих данных может помочь смягчить такие проблемы.
В случае несбалансированных данных класс «0» (класс большинства) может случайным образом получить недостаточную выборку, или класс «1» (класс меньшинства) может случайным образом получить избыточную выборку.
Случайная выборка может быть выполнена с заменой или без замены, потому что оба способа работают одинаково, согласно общей теории вероятности.
Иллюстрация 22 показывает идею недостаточной выборки для класса большинства и избыточной выборки для класса меньшинства. На практике, принятие решения о недостаточной или избыточной выборке, зависит от конкретного контекста задачи.
Расширенные методы также могут создавать синтетические наблюдения на основе существующих данных, и эти новые наблюдения позволяют сбалансировать класс меньшинства.