CFA - Неструктурированные (текстовые) данные
Рассмотрим работу с неструктурированными текстовыми данными в проектах больших данных - этапы подготовки и предварительной обработки текста для использования в машинном обучении, - в рамках изучения количественных методов по программе CFA (Уровень II).
Неструктурированные данные не организованы в какой-либо систематизированный формат, который может быть обработан моделями машинного обучения напрямую.
Неструктурированные данные (unstructured data) - это данные в форматах, предназначенных для использования человеком, а не для компьютерной обработки.
Неструктурированные данные составляют приблизительно 80% от общего объема данных, доступных сегодня.
Они могут быть в форме текста, изображений, видео и аудиофайлов. В отличие от структурированных данных, подготовка и первичная обработка таких данных более сложна.
Для анализа и использования в обучении модели машинного обучения, неструктурированные данные должны быть преобразованы в структурированные данные.
Далее мы используем текстовые данные для демонстрации подготовки и первичной обработки неструктурированных данных.
Очистка и предварительная обработка текстовых данных называется обработкой текста (text processing). Обработка текста по существу очищает и преобразует неструктурированные текстовые данные в структурированный формат.
Обработку текста можно разделить на две задачи: очистка и предварительная обработка.
Приведенная далее методика относится к текстовым данным на английском языке.
Подготовка текста (очистка).
Необработанные текстовые данные представляют собой последовательность символов и содержат неиспользуемые элементы, включая теги HTML, знаки пунктуации, пробелы, различные нечитаемые символы (например, знаки табуляции, разрывы строк) и т.д.
Важно очистить текстовые данные перед предварительной обработкой.
В Иллюстрации 6 показан пример текста с домашней страницы веб-сайта гипотетической компании Robots Are Us. Визуально текст кажется очищенным и читаемым для человека.
Иллюстрация 6. Пример текста на веб-странице компании Robots Are Us.

Пример текста на веб-странице компании Robots Are Us.
Тем не менее, исходный текст, который можно загрузить, не такой чистый.
Необработанный текст содержит теги HTML и элементы форматирования вместе с фактическим текстом. В Иллюстрации 7 показан необработанный исходный текст.
Иллюстрация 7. Необработанный исходный текст.

Необработанный исходный текст.
Первоначальным шагом при обработке текста является его очистка, которая включает в себя базовые операции по очистке текста путем удаления ненужных элементов из необработанного текста.
Для автоматизированной обработки текста часто используют регулярные выражения. Регулярное выражение (regular expression или regex) - это выражение, которое содержит определенную последовательность символов. Regex используется для поиска представляющих интерес шаблонов в данном тексте.
Например, regex-выражение <.*?> можно использовать для поиска всех тегов HTML (соответствующих шаблону <...>) в тексте.
GREP (global regular expression print) - это стандартная утилита, включенная в различные языки программирования и операционные системы, предназначенная для поиска шаблонов с использованием regex.
Как только шаблон найден, его можно удалить или заменить. Кроме того, усовершенствованные HTML-анализаторы (парсеры) и пакеты также доступны в популярных языках программирования, таких как R и Python, для решения этой задачи.
Следующие шаги описывают базовые операции процесса очистки текста.
1. Удаление тегов HTML: большинство текстовых данных извлекаются с веб-страниц, и загруженный текст содержит теги разметки HTML вперемешку с фактическим текстовым содержимым.
Первоначальная задача состоит в том, чтобы удалить (отбросить) теги HTML, которые не являются частью фактического текста, используя функции программирования или регулярные выражения.
В Иллюстрации 7 является тегом HTML, который можно идентифицировать и удалить с помощью regex. Обратите внимание, что при очистке в тексте нередко сохраняют некоторые теги HTML, обеспечивающие базовое форматирование текста.
2. Удаление знаков пунктуации: большинство знаков пунктуации не нужны для анализа текста и должны быть удалены.
Тем не менее, некоторые знаки пунктуации, такие как знаки процента, символы валют и знаки вопроса, могут быть полезны для обучения модели машинного обучения.
Эти знаки пунктуации должны быть заменены такими аннотациями, как /percentSign/, /dollarSign/ и /questionMark/ для сохранения их грамматического значения в тексте.
Такие аннотации сохраняют семантическое значение важных символов в тексте для дальнейших стадий обработки и анализа текста.
Важно отметить, что точки (periods, dots) в тексте необходимо тщательно обработать.
Точки в тексте могут использоваться для разных целей - для сокращений, ограничения предложений и десятичных разделителей. В зависимости от контекста, точки должны быть идентифицированы и надлежащим образом удалены или заменены.
В целом, точки после сокращений можно удалить, а точки, разделяющие предложения, нужно заменить аннотацией /endSentence/.
Некоторые знаки пунктуации, такие как дефис и нижнее подчеркивание, обычно не нужно удалять, чтобы сохранить объединенные знаком слова (например, e-mail).
Для удаления или замены знаков пунктуации часто используется regex.
3. Удаление чисел: если в тексте присутствуют цифры, их следует удалить или заменить аннотацией /number/.
Это помогает сообщить программе, что в тексте присутствует число, но фактическое значение самого числа бесполезно для классификации / анализа текста.
Такие операции имеют решающее значение для обучения модели машинного обучения.
В противном случае алгоритм будут рассматривать каждое число как отдельное слово, что может усложнить анализ или добавить шум.
Для удаления или замены чисел часто используется regex. Тем не менее, числа и десятичные разделители необходимо сохранить в тех случаях, когда представляющие интерес выходы модели являются фактическими числовыми значениями.
Одним из таких применений текста является извлечение информации (IE, information extraction), где цель состоит в том, чтобы извлечь соответствующую информацию из данного текста. Задачей IE может быть извлечение денежных сумм из финансовых отчетов, где фактические числовые значения имеют решающее значение.
4. Удаление пробелов и нечитаемых символов: в тексте могут быть дополнительные пробелы, знаки табуляции, пробелы перед текстом и после текста.
Дополнительные пробелы необходимо идентифицировать и удалить. Некоторые функции в языках программирования хорошо подходят или специально предназначены для удаления лишних пробелов из текста.
Например, в языке R есть функция «stripwhitespace».
В Иллюстрации 8 используется образец финансового текста, демонстрирующий преобразования, происходящие после применения каждой задачи процесса очистки текста.
К вымышленному необработанному финансовому тексту применяются 4 операции очистки, описанные выше. Как отмечалось ранее, сбор текста из интернета (web scraping) - это метод извлечения необработанного контента из интернет-источников, как правило, веб-страниц.
Важно отметить, что выбор и последовательность применения операций очистки имеют большое значение. Например, после удаления знаков пунктуации, выражение «1.2 million» преобразуется в «12 million».
В данном случае это приемлемо, поскольку последующая операция заменяет все числа на тег «/number/». Однако, если числа не заменяются такими тегами, операция удаления знаков пунктуации может повлиять на данные.
Иллюстрация 8. Пример процесса очистки англоязычного текста.

Пример процесса очистки англоязычного текста.
Первичная обработка текста (text wrangling).
Для дальнейшего изучения обработки текста необходимо определить понятия токенов и токенизации.
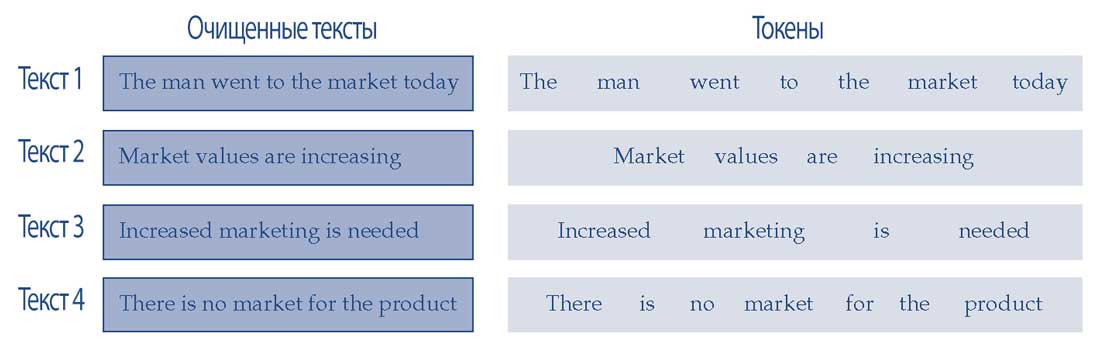
Токен (token) эквивалентен слову, а токенизация (tokenization) - это процесс разделения данного текста на отдельные токены. Другими словами, текст считается коллекцией токенов.
Токенизацию можно выполнить на уровне слов или символов, но чаще всего она выполняется на уровне слов.
В Иллюстрации 9 показаны образцы четырех очищенных текстов и их токенов.
Иллюстрация 9. Токенизация четырех текстов.
Подобно структурированным данным, текстовые данные также требуют нормализации. Процесс нормализации при обработке текста включает в себя следующее:
1. Преобразование букв в нижний регистр (lowercasing) удаляет различия между одинаковыми словами из-за верхнего и нижнего регистра. Это действие помогает алгоритмам соответствующим образом обрабатывать одни и те же слова (например, «The« и «the»).
2. Стоп-слова (stop words) - это такие часто используемые слова, как «the», «is» и «a». Стоп-слова не несут семантического значения для целей текстового анализа и обучения модели.
Однако, в зависимости от конечного использования обработанного текста, может быть важно сохранить стоп-слова в тексте, чтобы был понятен контекст соседних слов.
Для целей обучения модели стоп-слова обычно удаляются, чтобы уменьшить количество токенов, участвующих в обучающем наборе данных. Предопределенный список стоп-слов обычно уже включен в языки программирования, чтобы помочь справиться с этой задачей.
В некоторых случаях в список могут быть добавлены дополнительные стоп-слова, установленные на основе контента.
Например, слово «exhibit» может часто встречаться в финансовых отчетах, и хотя в общем случае оно не является стоп-словом, но в контексте отчетов его можно рассматривать как стоп-слово.
3. Стемминг или выделение основы слова (stemming) - это процесс преобразования различны форм слова в его базовую форму или основу (известную как stem).
Стемминг - это метод, основанный на правилах, и его результаты не обязательно должны быть лингвистически обоснованными.
Алгоритм Портера является самым популярным методом для стемминга.
Базовая форма слова может не совпадать с морфологическим корнем слова. Например, базовой формой слов «analyzed» и «analyzing» является «analyz» в соответствии с алгоритмом Портера. Точно так же британским вариантом основы слова «analysing» является «analys».
Стемминг доступен в языках R и Python. Пакет майнинга текста в R предоставляет функцию stemDocument, которая использует этот алгоритм.
4. Лемматизация (lemmatization) - это процесс преобразования форм слова в его морфологический корень (известный как лемма).
Лемматизация является алгоритмическим подходом и зависит от знания слова и структуры языка.
Например, леммой слов «analyzed» и «analyzing» является «analyze». Лемматизация требует больших вычислительных мощностей, чем стемминг.
Стемминг или лемматизация уменьшают повторение слов, появляющихся в различных формах, и сохраняют семантическую структуру текстовых данных.
В английском языке стемминг встречается чаще, чем лемматизация, поскольку его проще выполнить.
В текстовых данных разреженностью данных (sparseness) называют ситуацию, когда слова встречаются очень редко, что приводит к данным, состоящим из множества уникальных, низкочастотных токенов.
Оба метода уменьшают редкость данных, агрегируя многие редко встречающиеся слова в относительно менее разреженные основы или леммы, тем самым помогая обучать менее сложные модели машинного обучения.
После того, как очищенный текст нормализован, создается мешок слов. Мешок слов (BOW, bag-of-words) является основной процедурой, используемой для анализа текста.
По сути, это коллекция отдельных наборов токенов из всех текстов набора данных.
Мешок слов - это просто набор слов и он не отражает позицию или последовательность слов, присутствующих в тексте. Тем не менее, его удобно хранить в памяти и легко обрабатывать при анализе текста.
В Иллюстрации 10 показан мешок слов и преобразования, выполняющиеся на каждом этапе нормализации для очищенных текстов из Иллюстрации 9.
Обратите внимание, что количество слов уменьшается по мере применения шагов нормализации, что делает полученный мешок слов меньше и проще.
Иллюстрация 10. Формирование мешка слов (BOW) для четырех текстов, до и после процесса нормализации.
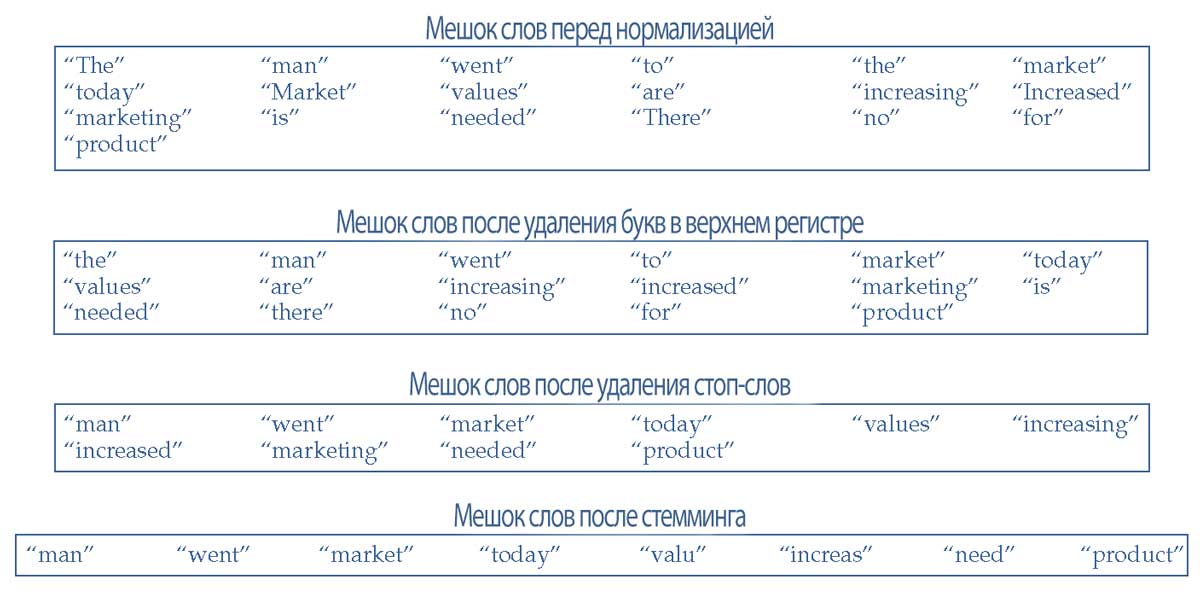
Формирование мешка слов (BOW) для четырех текстов, до и после процесса нормализации.
Последний этап предварительной обработки текста использует окончательный мешок слов после нормализации для создания терм-документной матрицы (DTM).
Терм-документная матрица (DTM, document term matrix) - это математическая матрица, похожая на таблицу структурированных данных, которую широко используют для текстовых данных.
Каждая строка матрицы представляет документ (или текстовый файл), а каждый столбец представляет токен (или терм).
Количество строк DTM равно количеству документов (или текстовых файлов) в наборе данных.
Количество столбцов равно количеству токенов из мешка данных, который создается с использованием всех документов из набора данных.
Ячейки матрицы могут содержать частоту (т.е. количество повторений), с которой токен встречается в документе.
Ячейки матрицы могут быть заполнены другими значениями, которые мы рассмотрим далее в этом чтении, в разделе посвященном финансовому прогнозированию.
Для понимания этой концепции полезно использовать большой набор данных.
На этом этапе неструктурированные текстовые данные преобразуются в структурированные данные, которые затем можно обрабатывать и использовать для обучения модели.
В Иллюстрации 11 показана DTM, построенная на основе полученного мешка слов четырех текстов из Иллюстрации 10.
Иллюстрация 11. DTM на основе четырех текстов и нормализованного мешка слов, заполненная частотой токенов.
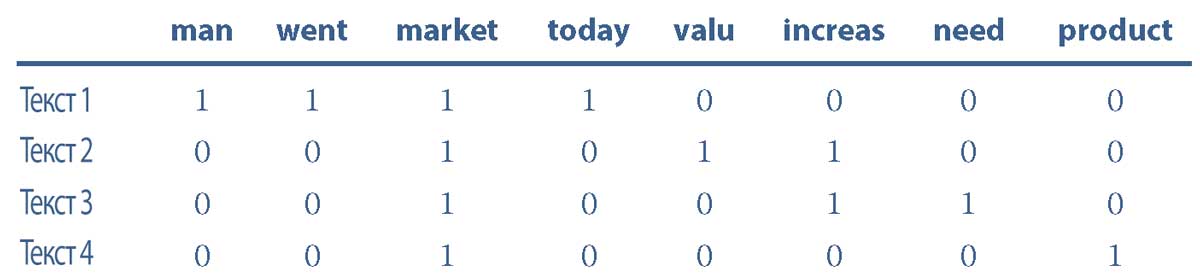
DTM на основе четырех текстов и нормализованного мешка слов, заполненная частотой токенов.
Как видно из Иллюстрации 10, мешок слов не представляет позиции или последовательность слов, что ограничивает его использование в некоторых расширенных методах обучения модели машинного обучения.
В нашем примере слово «no» рассматривается как токен и удаляется во время нормализации, потому что это стоп-слово. Следовательно, мы теряем в тексте отрицательное значение (например, «no market» в Тексте 4).
Чтобы преодолеть такие проблемы, можно использовать методику, называемую n-граммами. N-граммы (n-grams) - это представление последовательностей слов. Длина последовательности может варьироваться от 1 до \(n\).
- Когда используется одно слово, это юниграмма (unigram);
- последовательность с двумя словами - биграмма (bigram); и
- последовательность из 3 слов- это триграмма (trigram);
- и так далее.
Например, в Иллюстрации 10 показан мешок слов из юниграмм (\(n = 1\)).
Преимущество n-грамм заключается в том, что их можно использовать так же, как и юниграммы для построения мешка слов. На практике различные n-граммы можно объединить, чтобы сформировать мешок слов и в конечном итоге использовать его для построения DTM.
Иллюстрация 12 показывает юниграммы, биграммы и триграммы. В Иллюстрации 12 также показан комбинированный из юниграмм, биграмм и триграмм мешок слов для конкретного текста.
Перед построением n-грамм и мешка слов можно применить стемминг к очищенному тексту (не показано в Иллюстрации 12).
Иллюстрация 12. N-граммы в мешке слов.
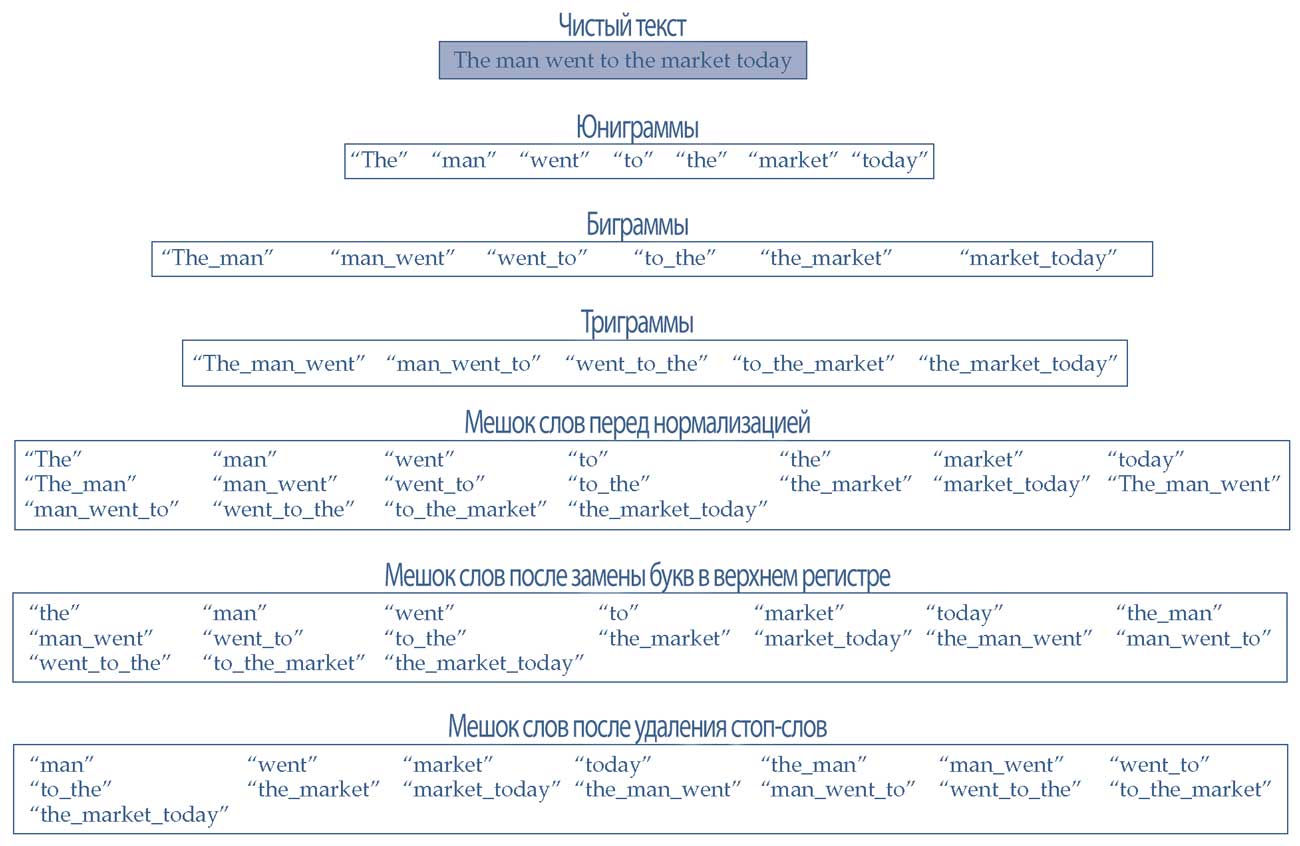
Реализация n-грамм меняет влияние нормализации на мешок слов. Даже после удаления изолированных стоп-слов, стоп-слова имеют тенденцию сохраняться, когда они прикреплены к соседним словам.
Например, «to_the» (Иллюстрация 12) - это токен биграммы, состоящий из стоп-слов, которые не будет удалены после применения предопределенного списка стоп-слов.
Пример 3. Подготовка и первичная обработка неструктурированных данных.
1. Вывод, созданный путем подготовки и первичной обработки текстовых данных, лучше всего описать как:
- A. таблицу данных.
- B. матрицу.
- C. терм-документную матрицу.
2. При очистке текста ситуации, в которых может потребоваться добавление аннотации, включают удаление:
- A. HTML-тегов.
- B. пробелов.
- C. знаков пунктуации.
3. Столбец терм-документной матрицы лучше всего описать как представление:
- A. токена.
- B. термина регуляризации.
- C. экземпляра.
4. Ячейку терм-документной матрицы лучше всего описать как содержащую:
- A. токен.
- B. количество токенов.
- C. количество экземпляров.
5. Нормализация текстовых данных включает в себя:
- A. удаление чисел.
- B. удаление пробелов.
- C. преобразование букв в нижний формат.
6. Когда некоторые слова очень редко встречаются в текстовых данных, методы, снижающие риск обучения очень сложных моделей, включают:
- A. стемминг.
- B. масштабирование.
- C. очистку данных.
7. Какое из следующих утверждений о токенизации является наиболее точным?
- A. Токенизация является частью процесса очистки текста.
- B. Токенизация чаще всего выполняется на уровне символов.
- C. Токенизация - это процесс разделения данного текста на отдельные токены.
Решение для части 1:
Ответ C верен. Целью подготовки и первичной обработки текстовых данных является преобразование неструктурированных данных в структурированные данные.
Вывод этих процессов представляет собой терм-документную матрицу (DTM), подходящую для считывания программами. Терм-документная матрица аналогична таблице данных для структурированных данных.
Решение для части 2:
Ответ C верен. Некоторые знаки пунктуации, такие как знаки процента, символы валют и знаки вопроса, могут быть полезны для обучения модели, поэтому такие знаки пунктуации следует заменять аннотациями.
Решение для части 3:
Ответ A верен. Каждый столбец матрицы DTM представляет собой токен из мешка слов, построенного с использованием всех документов из набора данных.
Решение для части 4:
Ответ B верен. Ячейка в матрице DTM содержит количество токенов, указанных в заголовках столбцов.
Решение для части 5:
Ответ C верен. Другие варианты связаны с очисткой текста.
Решение для части 6:
Ответ A верен. Стемминг, процесс преобразования форм слов в базовую форму слова, является одним из методов, который может решить описанную проблему.
Решение для части 7:
Ответ C верен по определению. Другие варианты не верны.