CFA - Оценка эффективности обучения модели
Рассмотрим оценку эффективности обучения модели машинного обучения в проекте больших данных, - в рамках изучения количественных методов по программе CFA (Уровень II).
Для валидации модели важно оценивать эффективность (качество) обучения модели или степень ее согласованности.
Мы рассмотрим несколько методов оценки эффективности модели, которые хорошо подходят для моделей бинарной классификации.
1. Анализ ошибок.
Для задач классификации анализ ошибок включает в себя вычисление четырех основных метрик оценки:
- истинно положительная (TP) ошибка,
- ложно положительная (FP) ошибка,
- истинно отрицательная (TN) ошибка и
- ложно отрицательная (FN) ошибка.
FP также называют ошибкой I рода, а FN называют ошибкой II рода.
В Иллюстрации 23 показана матрица неточностей (confusion matrix) - таблица, которая используется для суммирования значений этих четырех метрик.
Иллюстрация 23. Матрица неточностей для анализа ошибок.
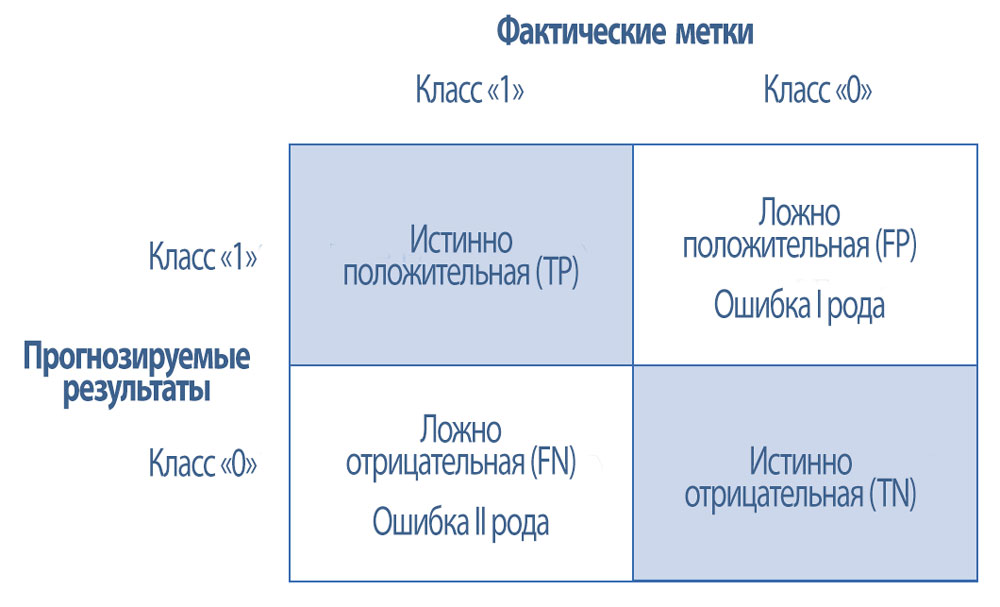
Матрица неточностей для анализа ошибок.
Можно рассчитать дополнительные показатели, такие как точность и отзывчивость. Предположим, что класс «0» является «не дефектным» продуктом, а класс «1» - «дефектным» продуктом.
Точность (precision) - это отношение правильно предсказанных позитивных классов ко всем предсказанным позитивным классам.
Точность полезна в ситуациях, когда стоимость FP или ошибки I рода высока - например, когда дорогой продукт не проходит проверку качества (прогнозируемый класс «1») и признается бракованным, но на самом деле он не имеет дефектов (фактический класс «0»).
Отзывчивость или чувствительность (recall) является отношением правильно предсказанных позитивных классов ко всем фактическим позитивным классам.
Отзывчивость полезна в ситуациях, когда стоимость FN или ошибки II рода высока, например, когда дорогой продукт проходит проверку качества (прогнозируемый класс «0») и поставляется важному клиенту, но на самом деле он является дефектным (фактический класс «1»).
Формулы для расчета показателей точности и отзывчивости:
Точность (P) = TP / (TP + FP). (3)
Отзывчивость (R) = TP / (TP + FN). (4)
Компромисс между точностью и отзывчивостью является предметом бизнес-решений и применения модели. Следовательно, для этого используются дополнительные показатели, которые обеспечивают общую оценку эффективности модели.
Два общих показателя эффективности модели - это точность и оценка F1.
Общая точность прогноза (accuracy) - это процентная доля правильно предсказанных классов из общего количества прогнозов.
Оценка F1 (F1 score) - это среднее гармоническое значение точности и отзывчивости.
Оценка F1 больше подходит (чем общая точность), когда в наборе данных наблюдается неравное распределение классов, и необходимо найти баланс между точностью и отзывчивостью.
Высокие оценки для обоих этих показателей предполагают хорошую эффективность модели. Для расчета общей точности и оценки F1 используются следующие формулы:
Общая точность = (TP + TN) / (TP + FP + TN + FN). (5)
Оценка F1 = (2 \(\times\) P \(\times\) R) / (P + R). (6)
Иллюстрация 24 показывает пример расчета показателей эффективности моделей.
Иллюстрация 24. Расчет метрик и оценок эффективности модели.
|
Наблюдение |
Фактические метки |
Прогнозируемые |
Классификация |
|---|---|---|---|
|
1 |
1 |
1 |
TP |
|
2 |
0 |
0 |
TN |
|
3 |
1 |
1 |
TP |
|
4 |
1 |
0 |
FN |
|
5 |
1 |
1 |
TP |
|
6 |
1 |
0 |
FN |
|
7 |
0 |
0 |
TN |
|
8 |
0 |
0 |
TN |
|
9 |
0 |
0 |
TN |
|
10 |
0 |
1 |
FP |
|
Фактические метки |
|||
|---|---|---|---|
|
Прогнозируемые результаты |
Класс «1» |
Класс «0» |
|
|
Класс «1» |
3 (TP) |
1 (FP) |
|
|
Класс «0» |
2 (FN) |
4 (TN) |
|
Показатели эффективности
TP = 3, FP = 1, FN = 2, TN = 4
P = 3 / (3 + 1) = 0.75
R = 3 / (3 + 2) = 0.60
Оценка F1 = (2 \(\times\) 0.75 \(\times\) 0.60) / (0.75 + 0.60) = 0.67
Общая точность = (3 + 4) / (3 + 1 + 4 + 2) = 0.70
В Иллюстрации 24, если бы все классы «1» были предсказаны правильно (без FP), точность была бы равна 1. Если бы все классы «0» были предсказаны правильно (без FN), отзывчивость была бы равна 1.
Таким образом, полученная оценка F1 была бы равна 1. Точность 0.75 и отзывчивость 0.60 указывают на то, что модель лучше работает при минимизации FP, чем FN ошибок.
Чтобы найти равновесие между точностью и отзывчивостью, рассчитывается оценка F1, которая равна 0.67. Оценка F1 близка к наименьшему значению из точности и отзывчивости, что дает модели более подходящую оценку, а не просто среднее арифметическое (точности и отзывчивости).
Общая точность, процентная доля правильных прогнозов (для обоих классов), сделанных моделью, равна 0.70. Общая точность была бы равна 1, если бы все прогнозы были правильными.
Поскольку количество классов «1» и «0» одинаково в наборе данных (то есть, это сбалансированный набор данных), общая точность в этом случае можно считать подходящим показателем эффективности.
Если количество классов в наборе данных неравное, следует использовать оценку F1 в качестве общего показателя эффективности для модели.
2. Характеристическая кривая обнаружения (ROC-характеристика).
Этот метод оценки эффективности модели включает в себя график кривой, показывающий компромисс между уровнем ложно положительных оценок (ось X) и истинно положительных оценок (ось Y) для различных точек отсечения, например, для прогнозируемой вероятности (\(p\)) в логистической регрессии.
Формулы для расчета ложно положительного коэффициента и истинно положительного коэффициента (обратите внимание, что истинно положительный коэффициент такой же, как отзывчивость):
Ложно положительный
коэффициент (FPR) = FP / (TN + FP) и (7)
Истинно положительный
коэффициент (TPR) = TP / (TP + FN). (8)
Если \(p\) из модели логистической регрессии для данного наблюдения больше, чем точка отсечения (или порог), то наблюдение классифицируется как класс = 1. В противном случае наблюдение классифицируется как класс = 0.
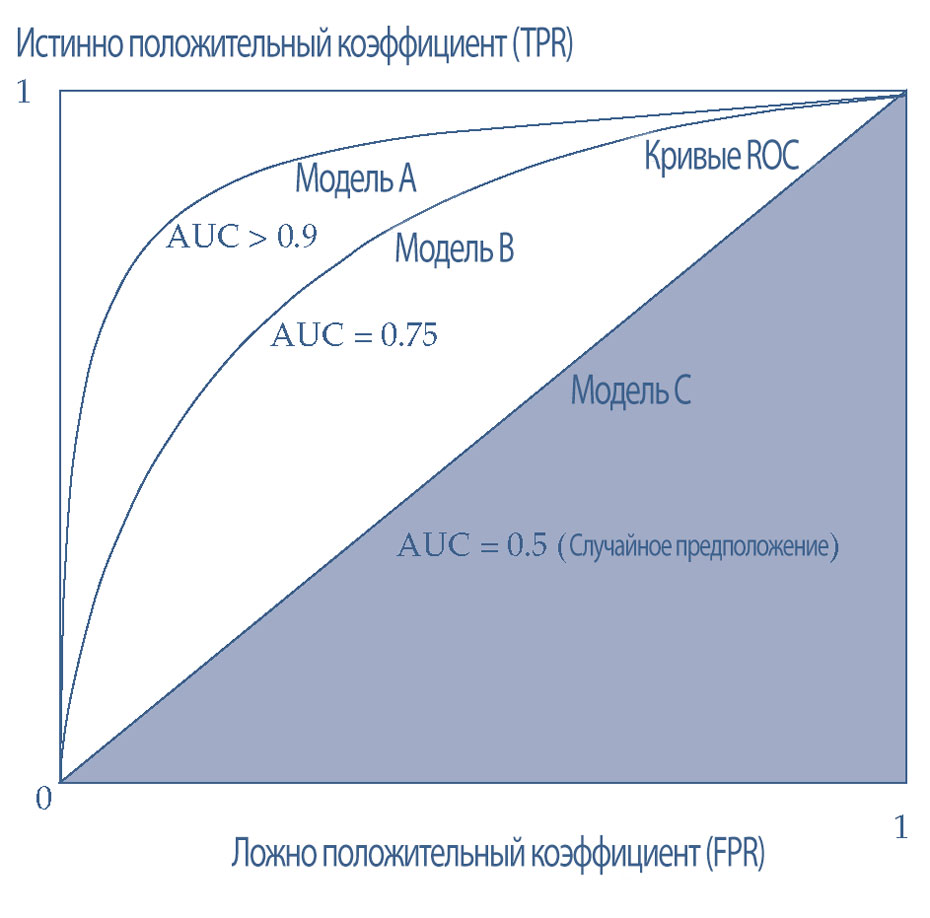
Форма кривой ROC (Receiver Operating Characteristic) дает представление об эффективности модели. Более выпуклая кривая указывает на лучшую эффективность модели.
Площадь под кривой (AUC, area under the curve) является показателем, который измеряет область под кривой ROC. Значение AUC, близкое к 1.0, указывает на почти идеальный прогноз, в то время как AUC 0.5 означает случайное предположение.
Иллюстрация 25 показывает три кривых ROC и их соответствующие значения AUC. Если рассмотреть формы кривых ROC и их значения AUC, становится очевидно, что Модель A (с наиболее выпуклой кривой ROC и AUC более 0.9 или 90%) является наиболее эффективной среди трех моделей.
Иллюстрация 25. Кривые ROC и AUC.
3. Среднеквадратическая ошибка (RMSE).
Этот показатель подходит для непрерывного прогнозирования данных и в основном используется для методов регрессии. Это единственная метрика, которая отражает в себе все ошибки прогнозирования в данных (\(n\)).
Среднеквадратическая ошибка (RMSE, root mean squared error) вычисляется путем поиска квадратного корня из среднего значения квадратных разностей между фактическими и прогнозируемыми значениями модели.
Небольшая RMSE указывает на потенциально лучшую эффективность модели. Формула для RMSE:
\( {\rm RMSE} = \dst \sqrt{ \sum^n_{i=1}
{ (\text{Прогноз}_i - \text{Факт}_i )^2 \over n} } \) (9)