CFA - Эффективность алгоритмов машинного обучения
Рассмотрим оценку эффективности алгоритмов машинного обучения, проблему переобучения алгоритмов ML и методы ее решения, - в рамках изучения количественных методов по программе CFA (Уровень II).
Алгоритмы машинного обучения обещают несколько преимуществ, связанных со структурированным статистическим подходом, при изучении и анализе структуры очень больших наборов данных.
Алгоритмы ML имеют возможность раскрывать сложные взаимодействия между переменными признаков и целевой переменной, а также могут быстро обрабатывать огромные объемы данных.
Кроме того, многие алгоритмы ML могут легко улавливать нелинейные связи и могут распознавать и предсказывать структурные изменения между признаками и целью.
Эти преимущества в основном обеспечиваются непараметрическими и нелинейными моделями, которые обеспечивают большую гибкость при выводе связей.
Однако гибкость алгоритмов ML имеет свою цену. Алгоритмы ML могут создавать чрезмерно сложные модели с результатами, которые трудно интерпретировать, могут быть чувствительными к шуму или частностям данных и могут слишком хорошо соответствовать обучающим данным.
Алгоритм ML, который слишком хорошо объясняет обучающие данных, обычно не будет хорошо предсказывать на основе новых данных. Эта проблема известна как переобучение (англ. 'overfitting'), и это означает, что алгоритм, хорошо работающий с обучающими данными, плохо делает выводы (обобщает) на основе новых данных.
Модель, которая хорошо делает выводы (обобщает) - это модель, которая сохраняет свою объясняющую силу при прогнозировании на основе данных вне выборки (то есть новых данных).
Переобученная модель (англ. 'overfit model') запоминает шум или случайные закономерности (колебания) в обучающих данных - т.е. включает их в изученные взаимосвязи.
Проблема заключается в том, что эти аспекты часто не применимы к новым данным, которые получает алгоритм, и это негативно влияет на способность модели делать выводы (объяснять), что снижает ее общую прогностическую ценность.
Таким образом, оценка эффективности любого алгоритма ML фокусируется на ошибках прогнозирования с использованием новых данных, а не на хорошем соответствии обучающим данным, на основе которых был настроен (т.е. обучен) алгоритм.
Обобщение (англ. 'generalization'), т.е. способность делать обоснованные выводы, является целью построения модели, поэтому проблема переобучения является проблемой достижения этой цели. Эти две концепции находятся в центре дальнейшего обсуждения.
Обобщение и переобучение.
Чтобы правильно описать обобщение и переобучение модели ML, важно отметить разделение набора данных, к которому будет применяться модель.
Набор данных обычно делится на три непересекающихся выборки:
- (1) обучающая выборка (training sample), используемая для обучения модели,
- (2) проверочная или валидационная выборка (validation sample) для проверки правильности и настройки модели, и
- (3) тестовая выборка (test sample) для тестирования способности модели хорошо прогнозировать новые данные.
Обучающую и проверочную выборки часто называют данными «в пределах выборки», а тестовую выборку обычно называют данными «вне выборки».
Далее мы вернемся к теме разбиения набора данных.
Чтобы быть правильной и полезной, любая контролируемая модель машинного обучения должна уметь обобщать далеко за пределами обучающих данных. Модель должна сохранять свою объяснительную силу при тестировании вне выборки.
Как уже упоминалось, одной из обычных причин неспособности обобщения является переобучение.
Думайте о переобучении как о заказе индивидуального костюма у портного, который подходит только одному человеку.
Если продолжить эту аналогию, недостаточное обучение (underfitting) аналогично созданию мешковатого костюма, который никому не подходит, тогда как надежное или хорошее обучение (good fitting) похоже на создание универсального костюма, который подходит всех людям схожего размера.
Концепции недостаточного обучения, переобучения и хорошего (или надежного) обучения показаны в Иллюстрации 3.
Недостаточное обучение означает, что модель не отражает взаимосвязи в данных.
Левый график показывает четыре ошибки в модели с недостаточным обучением (три неправильно классифицированных круга и один неправильно классифицированный треугольник).
Переобучение означает обучение модели до такой степени соответствия специфичным данным обучения, что модель начинает включать шум, исходящий от причудливых или ложных корреляций; модель ошибочно принимает случайность за структуру (паттерны) и взаимосвязи.
Алгоритм, возможно, запомнил данные, а не обучился на них, поэтому он идеально соответствует этим данным, но не научился прогнозировать на их основе. Таким образом, основными виновниками переобучения являются высокие уровни шума в данных и слишком высокая сложность модели.
Средний график показывает, что в этой переобученной модели отсутствуют ошибки.
Под сложностью модели (complexity) имеется в виду количество признаков, членов или ветвей в модели, а также то, является ли модель линейной или нелинейной (нелинейная модель более сложная).
По мере того, как модели становятся более сложными, риск переобучения увеличивается.
Хорошая обучаемая / надежная модель хорошо соответствует обучающим данным (в пределах выборки) и хорошо обобщает данные как вне выборки, таки в пределах выборки, с приемлемым уровнем ошибок.
Правый график показывает, что у модели с хорошим обучением есть только одна ошибка - неправильно классифицированный круг.
Иллюстрация 3. Недостаточное обучение, переобучение и хорошее обучение.

Недостаточное обучение, переобучение и хорошее обучение.
Ошибки и переобучение.
Чтобы отразить эти эффекты и калибровать степень обучения, исследователи данных сравнивают уровень ошибок в пределах и вне выборки в виде функции, как данных, так и алгоритма.
Общие ошибки в пределах выборки (\(E_{in}\)) - это отношение ошибок, сгенерированных предсказаниями установленной взаимосвязи, к количеству фактических целевых результатов по тестовой выборке.
Общие ошибки вне выборки (\(E_{out}\)) основаны на проверочной выборке или тестовой выборке.
Низкий уровень или отсутствие ошибок в пределах выборки, но большой уровень ошибок вне выборки свидетельствует о плохом обобщении.
Исследователи данных делят общую ошибку вне выборки на три источника:
- Ошибка смещения (bias error) - степень, в которой модель подходит обучающим данным. Алгоритмы с ошибочными допущениями вызывают высокую ошибку смещения с плохим приближением, приводя к недостаточному обучению и высокой ошибке в пределах выборки.
- Ошибка дисперсии (variance error) - насколько изменчивы результаты модели в ответ на использование новых данных из проверочных и тестовых выборок. Нестабильные модели приводят к шуму и высокой дисперсии, вызывая переобучение и высокую ошибку вне выборки.
- Базовая ошибка (base error) из-за случайности в данных.
Кривая обучения (learning curve) показывает уровень точности (accuracy rate) (= 1 - уровень ошибок) в проверочных и тестовых выборках (то есть, вне выборки) относительно объема данных в обучающей выборке, поэтому этот коэффициент полезен для описания недостаточного обучения или переобучения в виде функции ошибок смещения и ошибок дисперсии.
Если модель надежна, точность вне выборки увеличивается по мере увеличения размера обучающих данных.
Это подразумевает, что уровни ошибок, возникающих в проверочных и тестовых выборках (\(E_{out}\)), и в обучающей выборке (\(E_{in}\)) сходятся друг к другу и к желаемому уровню ошибок (иными словами, к базовой ошибке).
В модели с недостаточным обучением с высокой ошибкой смещения, показанной в левой панели Иллюстрации 4, высокий уровень ошибок приводит к конвергенции (схождению) ниже желаемого уровня точности.
Добавление большего числа обучающих выборок не улучшит модель до желаемого уровня эффективности.
В модели с переобучением с высокой ошибкой дисперсии, показанной в средней панели Иллюстрации 4, уровни ошибок проверочной выборки и выборки обучения не сходятся.
При построении моделей исследователи данных пытаются одновременно минимизировать как ошибки смещения, так и ошибки дисперсии при выборе алгоритма с хорошей прогнозирующей или классифицирующей силой, как видно в правой панели Иллюстрации 4.
Иллюстрация 4. Кривые обучения: точность в проверочных и обучающих выборках.
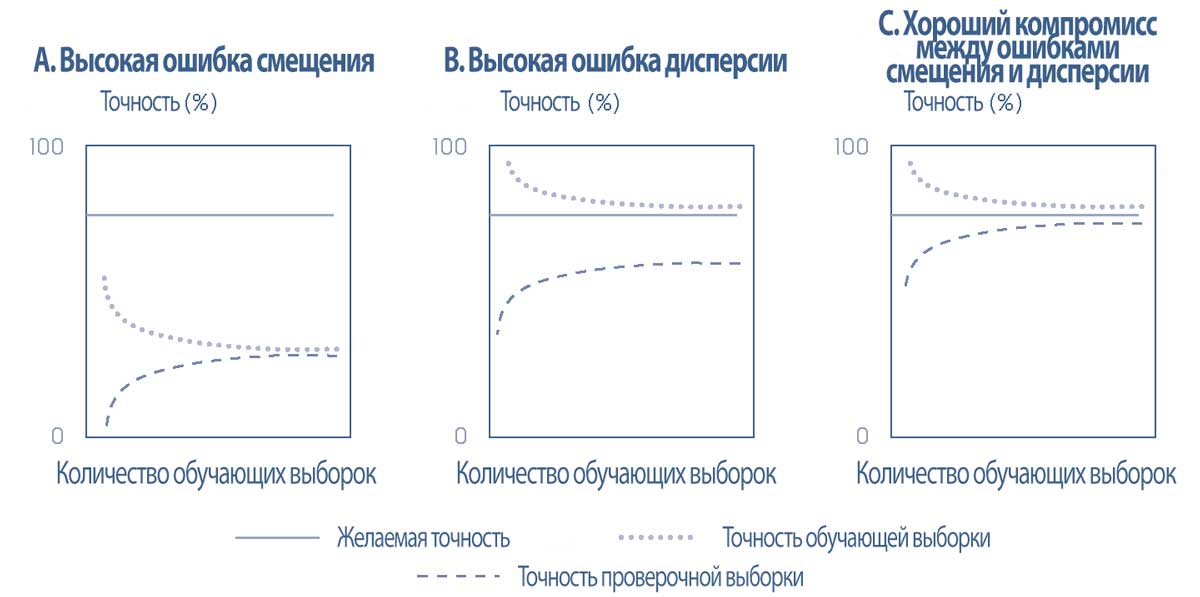
Кривые обучения: точность в проверочных и обучающих выборках.
Уровень ошибок вне выборки также является функцией сложности модели. По мере увеличения сложности в обучающем наборе уровень ошибок (\(E_{in}\)) падает, а ошибка смещения сокращается.
Однако по мере увеличения сложности в тестовом наборе уровень ошибок (\(E_{out}\)) растет и ошибка дисперсии также растет.
Как правило, линейные функции более восприимчивы к ошибке смещения и недостаточному обучению, в то время как нелинейные функции более подвержены ошибке дисперсии и переобучению.
Следовательно, оптимальная точка сложности модели находится там, где кривые ошибок смещения и дисперсии пересекаются, а уровни ошибок в пределах и вне выборки сводятся к минимуму.
Кривая обучаемости или подгонки (fitting curve) показывает, как ошибки соотносятся со сложностью модели. Она показывает уровни ошибок в пределах и вне выборки (\(E_{in}\) и \(E_{out}\)) на оси Y, относительно сложности модели на оси X, представлена в Иллюстрации 5 и показывает этот компромисс.
Иллюстрация 5. Кривая обучаемости (подгонки) показывает компромисс между ошибками смещения и дисперсии и сложностью модели.
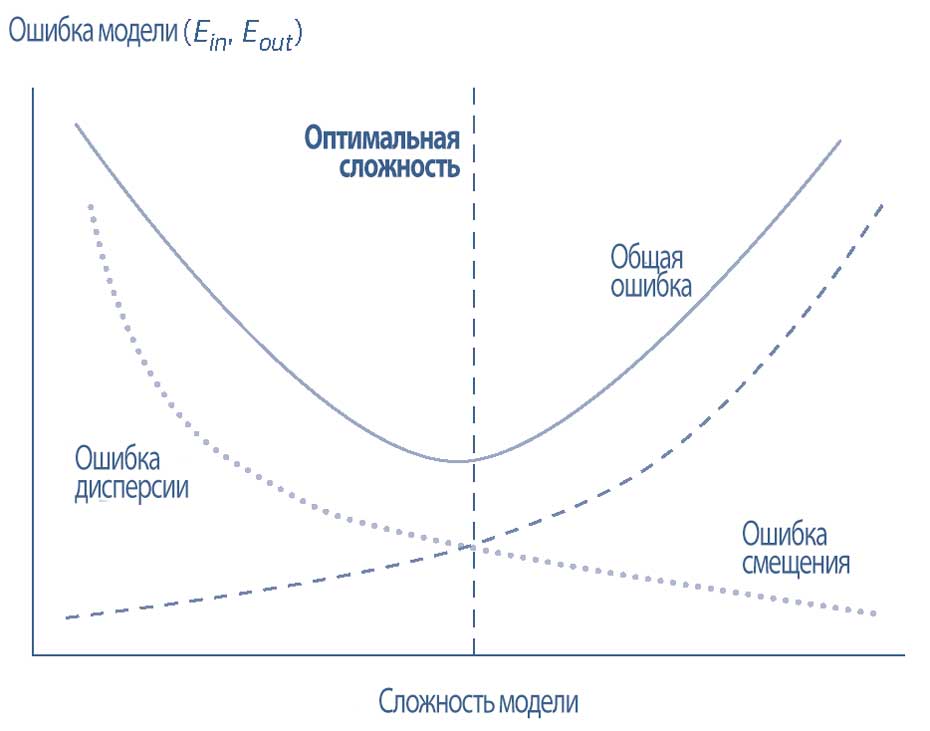
Оптимальная точка - это точка кривой, непосредственно перед тем, как уровень общей ошибки начнет расти (из-за увеличения ошибки дисперсии).
Поиск оптимальной точки (управление риском переобучения) является основной частью процесса машинного обучения и ключом к успешному обобщению.
Исследователи данных находятся в поиске компромисса между переобучением и обобщением, который также можно описать как компромисс между стоимостью (разница между уровнями ошибок в пределах и вне выборки) и сложностью.
Они используют компромисс между стоимостью и сложностью для калибровки и визуализации недостаточного обучения и переобучения, а также для оптимизации своих моделей.
Предотвращение переобучения в контролируемом машинном обучении.
Мы увидели, что переобучение ухудшает обобщение, но потенциал переобучения является эндемичным для процесса контролируемого машинного обучения из-за наличия шума.
Итак, как исследователи данных борются с этим риском?
Для уменьшения переобучения используются два общих метода:
- (1) предотвращение того, чтобы алгоритм стал слишком сложным во время отбора и обучения, что требует оценки сложностей из-за переобучения, и
- (2) правильная выборка данных, достигнутая с использованием перекрестной проверки или кросс-валидации (cross-validation) - метода оценки ошибки вне выборки непосредственно путем определения ошибки в проверочных выборках.
Первая стратегия происходит из принципа решения проблем "бритва Оккама" (Occam's razor), согласно которому самое простое решение обычно является самым правильным.
В контролируемом машинном обучении это означает ограничение количества признаков и пенализирующих алгоритмов, которые являются слишком сложными или слишком гибкими. Эти ограничения позволяют включить только те параметры, которые уменьшают ошибку вне выборки.
Вторая стратегия происходит из принципа уменьшения смещения выборки - то есть, стремления избежать смещения выборки. Но смещение может проникнуть в машинное обучение многими способами.
Задача состоит в том, чтобы иметь достаточно большой набор данных, чтобы сделать возможным обучение и тестирование на репрезентативных выборках.
Нерепрезентативная выборка или уменьшение размера обучающей выборки могут скрыть ее истинные закономерности (паттерны), тем самым увеличивая смещение.
В контролируемом машинном обучении методика снижения смещения выборки заключается в тщательном разделении набора данных на три группы:
- (1) обучающая выборка - набор размеченных обучающих данных, где известна целевая переменная (\(Y\));
- (2) проверочная или валидационная выборка - набор данных, используемый для выбора структурных вариантов согласно степени сложности модели, сравнения различных решений и настройки выбранной модели, что в совокупности позволяет проверить правильность (выполнить валидацию) модели; и
- (3) тестовая выборка - набор данных, предназначенный для тестирования, что позволяет подтвердить прогнозирующую или классифицирующую силу модели.
Цель, конечно, состоит в том, чтобы запустить тестируемую модель на свежих данных из той же области.
Чтобы смягчить проблему таких изымаемых выборок (holdout samples) (т.е., выборок данных, не используемых для обучения модели), которые слишком сильно уменьшают размер обучающих данных, исследователи используют специальные методы перекрестной проверки.
Одним из таких методов является k-кратная перекрестная проверка или k-кратная кросс-валидация (k-fold cross-validation), в которой данные (исключая тестовую выборку и свежие данные) случайным образом сортируются, а затем делятся на \(k\) одинаковых подвыборок, из которых \(k-1\) выборок используются в качестве обучающих выборок и 1 выборка, \(k\)-ая, используется в качестве проверочной (валидационной) выборки.
Обратите внимание, что \(k\) обычно устанавливают равным 5 или 10.
Затем этот процесс повторяется \(k\) раз, что помогает минимизировать как смещение, так и дисперсию, за счет того, что каждая точка данных используется в обучающем наборе \(k-1\) раз и в проверочном наборе 1 раз.
Среднее значение \(k\) ошибок валидации (среднее \(E_{val}\)) затем принимается в качестве разумной оценки ошибки вне выборки модели ((\(E_{out}\)).
Ограничением k-кратной кросс-валидации является то, что ее нельзя использовать с данными временных рядов, где только самые последние ряды можно разумно использовать для проверки (валидации) модели.
В целом, снижение риска переобучения за счет исключения чрезмерной ошибки вне выборки, имеет решающее значение для создания модели контролируемого машинного обучения, которая хорошо обобщает свежие наборы данных, взятые из того же распределения.
Основными методами, используемыми для снижения риска переобучения при построении модели, являются снижение сложности (или регуляризация) и перекрестная проверка (кросс-валидация).
Пример 2. Оценка эффективности алгоритма ML.
Шрея Ананд - портфельный менеджер в инвестиционной фирме со штаб-квартирой в Мумбаи. Она управляет высокодоходным фондом для богатых клиентов.
Ананд обладает некоторыми знаниями о науке о данных из своих университетских исследований.
Она заинтересована в классификации компаний из фондового индекса NIFTY 200 (индекс компаний крупной и средней капитализации, зарегистрированных на Национальной фондовой бирже Индии) по двум категориям:
- увеличение дивидендов и
- отсутствие дивидендов.
Она собирает данные для обучения, валидации и тестирования модели на основе ML, которая состоит из 1,000 наблюдений за компаниями NIFTY 200, каждое из которых состоит из 25 признаков (фундаментальных и технических) и размеченной цели (увеличение дивидендов или отсутствие увеличения дивидендов).
После обучения своей модели Ананд обнаруживает, что хотя модель хорошо справляется с правильной классификацией при использовании обучающей выборки, она плохо работает с новыми данными.
После консультаций с коллегами по этому вопросу, Ананд получила противоречивые объяснения того, что представляет собой хорошее обобщение в модели ML:
- Утверждение 1. Модель сохраняет свою объяснительную силу при прогнозировании с использованием новых данных (то есть, вне выборки).
- Утверждение 2. Модель показывает низкую объяснительную силу после обучения с использованием данных в пределах выборки (то есть, обучающих данных).
- Утверждение 3. Модель теряет свою объяснительную силу при прогнозировании с использованием новых данных (то есть, вне выборки).
1. Какое утверждение наиболее точное?
- A. Утверждение 1.
- B. Утверждение 2.
- C. Утверждение 3.
2. Модель Ананд, скорее всего, теряет свою ценность в результате следующего:
- A. Недостаточное обучение и ошибка смещения.
- B. Переобучение и ошибка дисперсии.
- C. Переобучение и ошибка смещения.
3. Какое из следующих действий может решить проблему Ананд?
- A. Оценить и включить в модель штраф, который уменьшается в размере вместе с количеством включенных признаков.
- B. Использовать методику k-кратной кросс-валидации для оценки ошибки вне выборки, а затем соответствующим образом настроить модель.
- C. Использовать модель неконтролируемого обучения.
Решение для части 1:
Ответ А, Утверждение 1, верен. Ответ B, Утверждение 2, неверен, потому что он описывает плохо обученную модель с высоким смещением.
Ответ C, Утверждение 3, неверен, потому что он описывает переобученную модель с плохим обобщением.
Решение для части 2:
Ответ B верен. Модель Ананд хороша в правильной классификации при использовании обучающей выборки, но она не очень хорошо работает с использованием новых данных.
Модель переобучена, поэтому она имеет высокую ошибку дисперсии.
Решение для части 3:
Ответ B верен. Ответ А неверен, потому что штраф должен увеличиваться в размере вместе с количеством включенных признаков.
Ответ C неверен, потому что Ананд использует размеченные данные для классификации, а модели неконтролируемого обучения не используют размеченные данные.