CFA - Что такое машинное обучение?
Рассмотрим фундаментальные концепции машинного обучения (ML), включая определение и обзор ключевых типов машинного обучения, таких как контролируемое и неконтролируемое ML, - в рамках изучения количественных методов по программе CFA (Уровень II).
Определение машинного обучения.
Статистические подходы и методы машинного обучения анализируют наблюдения, чтобы выявить лежащие в основе этих наблюдений процессы; однако они расходятся в своих допущениях, терминологии и методах.
Статистические подходы зависят от основополагающих допущений и явных моделей структуры, таких как наблюдаемые выборки, которые, как предполагается, взяты из указанного базисного распределения вероятности. Эти априорные ограничительные допущения могут быть нарушены в реальности.
См. также:
Напротив, машинное обучение (ML, machine learning) стремится извлечь знания из больших объемов данных с меньшим количеством таких ограничений. Целью алгоритмов машинного обучения является автоматизация процессов принятия решений путем обобщений (то есть «обучения») из известных примеров, чтобы определить основополагающую структуру в данных.
Акцент делается на способность алгоритма генерировать структуру или прогнозы из данных без какой-либо помощи человека. Элементарный способ представить себе алгоритм ML - это:
«найти паттерн [т.е. повторяющуюся структуру], применить паттерн».
Методы машинного обучения лучше, чем статистические подходы (такие как линейная регрессия), подходят для решения задач со многими переменными (высокая размерность) или с высокой степенью нелинейности.
Алгоритмы ML особенно хороши в обнаружении изменений, даже в очень нелинейных системах, поскольку они могут обнаружить предварительные условия негодности модели или предвидеть вероятность переключения режима модели.
Машинное обучение в целом разделено на три различных класса методов: контролируемое обучение, неконтролируемое обучение и глубокое обучение / обучение с подкреплением.
Определение контролируемого машинного обучения.
Контролируемое машинное обучение (англ. 'supervised machine learning') включает в себя алгоритмы ML, которые находят и выводят паттерны (т.е. образцы структуры или закономерности. Также упоминается как «образы») между набором входных данных (переменные \(X\)) и желаемым выводом (\(Y\)). Выведенный паттерн затем используется для отображения заданного набора входных данных в прогнозируемом выводе.
Контролируемое обучение требует размеченного набора данных (англ. 'labeled dataset'), который содержит соответствующие наборы наблюдаемых входных данных и связанного с ними вывода (выходных данных). Применение алгоритма ML к этому набору данных, чтобы найти и вывести паттерн между входными данными и выводом, называется «обучением» алгоритма.
После обучения алгоритма выведенный паттерн можно использовать для прогнозирования выходных значений на основе новых входных данных (то есть тех входных данных, которых нет в обучающем наборе данных).
Множественная регрессия является примером контролируемого обучения. Модель регрессии принимает соответствующие данные (\(X, Y\)) и использует их для расчета параметров, которые характеризуют взаимосвязь между \(Y\) и \(X\).
Рассчитанные параметры могут затем использоваться для прогнозирования \(Y\) - для нового, отличающегося набора данных \(X\).
Разница между прогнозируемым и фактическим \(Y\) используется для оценки того, насколько хорошо регрессионная модель предсказывает значения вне выборки (то есть, используя новые данные).
Терминология, используемая в алгоритмах ML, отличается от той, что используется в регрессионном анализе. Иллюстрация 1 дает визуальное представление о процессе контролируемого обучения модели и соответствие терминологии регрессии с терминологией ML.
Иллюстрация 1. Обзор процесса контролируемого машинного обучения.
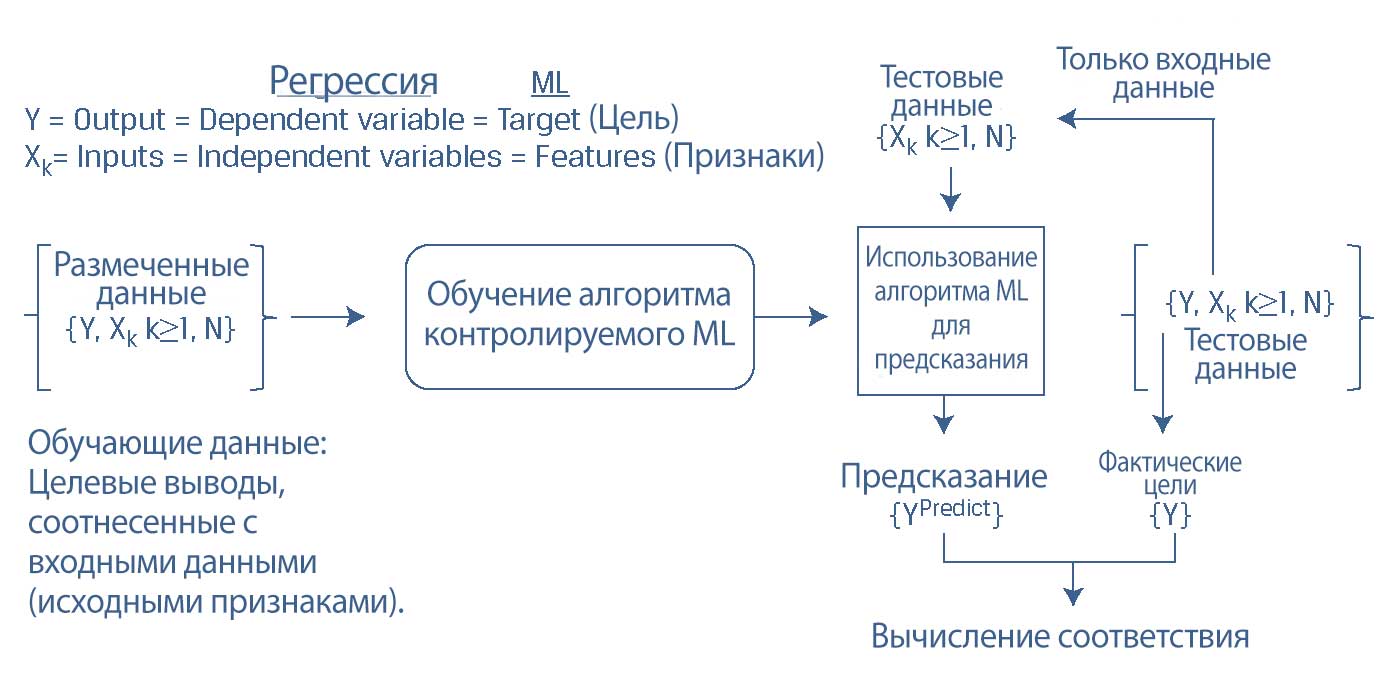
Обзор процесса контролируемого машинного обучения.
В контролируемом машинном обучении зависимая переменная \(Y\) является целью (target), а независимые переменные \(X\) известны как признаки (features).
Размеченные данные (обучающий набор данных, training dataset) используются для обучения алгоритма контролируемого ML, чтобы вывести правила прогнозирования на основе паттернов.
Вычисление соответствия модели ML осуществляется с использованием размеченных тестовых данных (labeled test data), в которых прогнозируемые цели (\(Y^{Predict}\)) сравниваются с фактическими целями (\(Y^{Actual}\)).
Примером контролируемого обучения является случай, когда алгоритмы ML используются для прогнозирования того, являются ли операции по кредитным картам мошенническими или законными.
В примере с кредитной картой цель представляет собой двоичную (бинарную) переменную со значением 1 для «мошенничества» или 0 для «законности».
Здесь признаками являются характеристики операции.
Выбранный алгоритм ML использует эти элементы данных для обучения модели, чтобы более точно прогнозировать вероятность мошенничества в новых операциях.
Программа машинного обучения «учится на опыте», если процент правильно предсказанных операций по кредитной карте увеличивается по мере увеличения количества входных данных, поступающих их растущей базы данных кредитных карт.
Одним из возможных применений алгоритмов ML является подбор модели логистической регрессии, чтобы обеспечить оценку вероятности того, что операция является мошеннической.
Контролируемое обучение можно разделить на две категории решения задач - регрессия и классификация. Различие между ними, определяется характером целевой переменной (\(Y\)).
- Если целевая переменная является непрерывной, то задача является регрессией (даже если используемая техника ML не является «регрессией»; обратите внимание на этот нюанс терминологии ML).
- Если целевая переменная является категориальной или порядковой (то есть категорией ранга), то это - задача классификации.
Задачи регрессии и классификации используют различные методы ML.
Регрессия фокусируется на прогнозировании непрерывных целевых переменных. Большинство читателей уже знакомы с несколькими моделями линейной регрессии (например, метод наименьших квадратов), но существуют другие контролируемые методы обучения, включая нелинейные модели.
Эти нелинейные модели полезны для решения задач, включающих большие наборы данных с большим количеством признаков, многие из которых могут коррелировать между собой.
Некоторые примеры задач, относящихся к категории регрессии, используют историческую доходность фондового рынка, чтобы прогнозировать показатели цен на акции или используют исторические финансовые коэффициенты корпораций для прогнозирования вероятности дефолта их облигаций.
Классификация фокусируется на сортировке наблюдений по различным категориям.
В задаче регрессии, когда зависимая переменная (цель) является категориальной, модель, связывающая результат с независимыми переменными (признаками), называется «классификатором» (classifier).
Вы уже должны быть знакомы с логистической регрессией как с типом классификатора. Многие модели классификации являются бинарными классификаторами, как в случае обнаружения мошенничества в операциях по кредитным картам.
Классификация по нескольким категориям не является редкостью, как в случае с классификацией компаний по нескольким категориям кредитного рейтинга.
При назначении рейтингов переменная результата является порядковой, то есть категории имеют отчетливый порядок или ранжирование (например, от низкой до высокой кредитоспособности). Порядные переменные являются промежуточными между категориальными переменными и непрерывными переменными по шкале измерений.
Определение неконтролируемого машинного обучения.
Неконтролируемое машинное обучение (англ. 'unsupervised machine learning') - это машинное обучение, которое не использует размеченные данные.
Если более формально, при неконтролируемом обучении у нас есть входные данные (\(X\)), которые используются для анализа без участия какой-либо цели (\(Y\)).
При неконтролируемом обучении алгоритм стремится обнаружить структуру в самих данных, поскольку в алгоритм ML не передаются размеченные данные для обучения.
Таким образом, неконтролируемое обучение полезно для изучения новых наборов данных, поскольку оно может дать экспертам-людям понимание набора данных, слишком большего или слишком сложного для визуализации.
Два важных типа задач, которые хорошо подходят для неконтролируемого машинного обучения, - это уменьшение размера данных и сортировка данных в кластеры, известные как уменьшение размерности и кластеризация, соответственно.
Уменьшение размерности (англ. 'dimension reduction') фокусируется на уменьшении количества признаков при сохранении вариативности наблюдений, чтобы сохранить информацию, содержащуюся в вариативности оставшихся признаков.
Уменьшение размерности может иметь несколько целей.
Его можно применять к данным с большим количеством признаков для получения представления более низкого размера (то есть с меньшим количеством признаков), например, чтобы его можно было вывести на одном экране компьютера.
Уменьшение размерности также используется во многих количественных инвестиционных задачах и задачах управления рисками, где очень важно определить наиболее важные прогностические факторы, лежащие в основе движения цен на активы.
Кластеризация (англ. 'clustering') фокусируется на сортировке наблюдений по группам (кластерам) так, чтобы наблюдения в одном кластере больше похожи друг на друга, чем на наблюдения в других кластерах.
Группы формируются на основе набора критериев, которые могут быть или не быть предварительно определенными (например, количество групп).
Менеджеры активов используют кластеризацию для сортировки компаний по группам, основанным на данных (например, на основе данных из финансовой отчетности или корпоративных характеристик), а не по традиционным группам (например, на основе отраслевых секторов или стран).
Определение глубокого обучения и обучения с подкреплением.
В области искусственного интеллекта, дополнительные категории алгоритмов машинного обучения отличаются своей сложностью.
При глубоком или глубинном обучении (англ. 'deep learning') изощренные алгоритмы решают сложные задачи, такие как классификация изображений, распознавание лица, распознавание речи и обработка естественного языка.
Глубокое обучение основано на нейронных сетях (NN, neural networks), также называемых искусственными нейронными сетями (ANN, artificial neural networks) - алгоритмах ML с высокой гибкостью, которые успешно применяются к различным контролируемым и неконтролируемым задачам, характеризующимся большими наборами данных, нелинейностью и взаимодействием между признаками.
При обучении с подкреплением компьютер учится на взаимодействии с самим собой или данными, сгенерированными одним и тем же алгоритмом.
Принципы глубокого обучения и обучения с подкреплением были объединены, чтобы создавать эффективные алгоритмы для решения ряда очень сложных задач в робототехнике, здравоохранении и финансах.
Обзор алгоритмов машинного обучения. Как выбрать подходящий алгоритм ML?
Иллюстрация 2 - это руководство по различным алгоритмам машинного обучения. Алгоритмы сгруппированы по типу алгоритма (контролируемый или неконтролируемый) и типу переменных (непрерывная, категориальная или оба типа).
Мы не будем разбирать линейную или логистическую регрессию, так как они рассмотрены в соответствующих чтениях количественных методов:
См. также:
Расширенные разновидности линейной регрессии, такие как пенализированная регрессия и Лассо-регрессия (LASSO, least absolute shrinkage and selection operator), а также другие алгоритмы ML, показанные в Иллюстрации 2, будут рассмотрены в дальнейшем в этом чтении.
Иллюстрация 2. Руководство по алгоритмам машинного обучения (ML).
|
Тип алгоритма ML |
||
|---|---|---|
|
Переменные |
Контролируемые (есть целевая переменная) |
Неконтролируемые (нет целевой переменной) |
| Непрерывные |
Регрессия
|
Уменьшение размерности
Кластеризация |
| Категориальные |
Классификация
|
Уменьшение размерности
Кластеризация |
| Непрерывные или категориальные | ||
Пример 1. Обзор машинного обучения.
1. Что из перечисленного лучше всего описывает машинное обучение?
Машинное обучение:
- A. это тип компьютерного алгоритма, используемый только для линейной регрессии.
- B. представляет собой набор алгоритмических подходов, направленных на создание структуры или прогнозов на основе данных без вмешательства человека путем поиска паттерна (образца структуры), а затем применения паттерна.
- C. это набор компьютерных подходов, адаптированных к извлечению информации из линейных размеченных наборов данных.
2. Какое из следующих утверждений наиболее точное?
При попытке обнаружить группировки данных без какой-либо целевой переменной (\(Y\)):
- A. используется неконтролируемый алгоритм ML.
- B. используется алгоритм ML, в который передаются размеченные обучающие данные.
- C. используется контролируемый алгоритм ML.
3. Какое из следующих утверждений о контролируемом обучении, лучше всего отличает его от неконтролируемого обучения?
Контролируемое обучение означает:
- A. обучение по размеченным данным, чтобы вывести правила прогнозирования на основе паттернов.
- B. обучение по неразмеченным данным, чтобы вывести правила прогнозирования на основе паттернов.
- C. обучение по неразмеченным данным путем обнаружения базовой структуры в самих данных.
4. Что из следующего лучше всего описывает уменьшение размерности?
Уменьшение размерности:
- A. фокусируется на классификации наблюдений из набора данных по известным группам с использованием размеченных обучающих данных.
- B. фокусируется на кластеризации наблюдений из набора данных по неизвестным группам с использованием размеченных обучающих данных.
- C. фокусируется на уменьшении количества признаков в наборе данных при сохранении вариативности наблюдений, чтобы сохранить информацию, содержащуюся вариативности оставшихся признаков.
Решение для части 1:
Ответ B верен. Ответ А неверен, потому что алгоритмы машинного обучения обычно не используются для линейной регрессии.
Ответ C неверен, потому что машинное обучение не ограничивается извлечением информации из линейных размеченных наборов данных.
Решение для части 2:
Ответ A верен. Ответ B неверен, потому что термин «размеченные обучающие данные» означает, что в алгоритм передается цель (\(Y\)).
Ответ C неверен, потому что контролируемый алгоритм ML предназначен для прогнозирования целевой переменной (\(Y\)).
Решение для части 3:
Ответ A верен. Ответ B неверен, потому что контролируемое обучение использует размеченные обучающие данные.
Ответ C неверен, потому что описывает неконтролируемое обучение.
Решение для части 4:
Ответ C верен. Ответ A неверен, потому что он описывает классификацию, а не уменьшение размерности.
Ответ B неверен, потому что он описывает кластеризацию, а не уменьшение размерности.