CFA - Как выбрать подходящий алгоритм машинного обучения?
Рассмотрим порядок принятия решения при выборе алгоритма машинного обучения, соответствующего поставленной задаче, - в рамках изучения количественных методов по программе CFA (Уровень II).
Иллюстрация 37 содержит упрощенную блок-схему принятия решения при выборе подходящего алгоритма среди алгоритмов машинного обучения, которые обсуждались ранее.
Прямоугольники со скругленными углами и светлым контуром содержат контролируемые алгоритмы ML; с темным контуром - неконтролируемые алгоритмы ML. Ключевые вопросы, которые следует учитывать при выборе, показаны в остальных прямоугольниках.
Иллюстрация 37. Стилизованная схема принятия решений при выборе алгоритма ML.
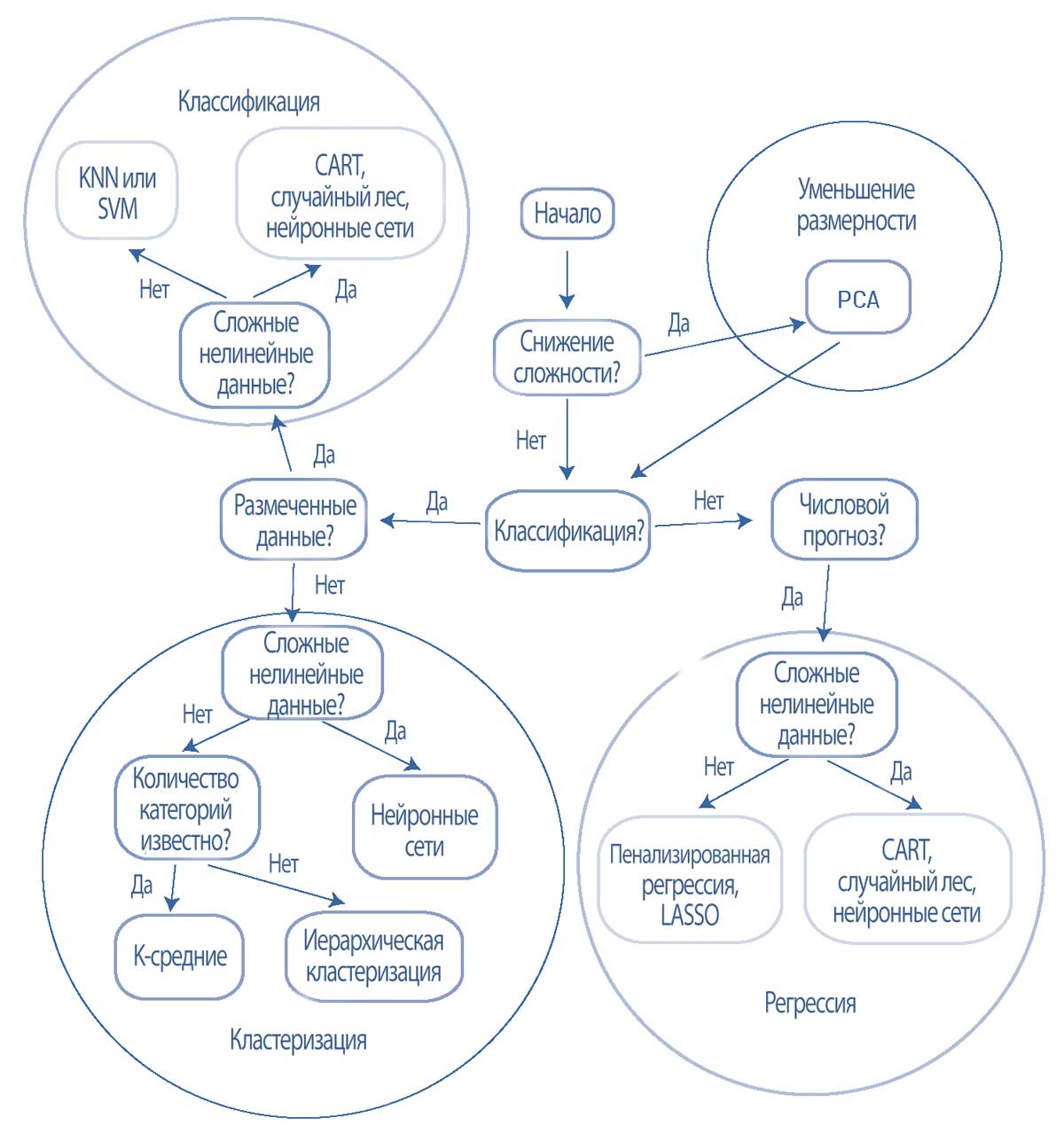
Стилизованная схема принятия решений при выборе алгоритма ML.
Во-первых, нужно начать с вопроса, являются ли данные сложными, т.е. имеющими много признаков, которые сильно коррелируют друг с другом?
Если да, то уместно уменьшение размерности с использованием анализа главных компонентов.
Далее, является ли задача классификацией или числовым прогнозом?
Если это числовой прогноз, то в зависимости от того, имеют ли данные нелинейные характеристики, выбор алгоритма осуществляется из набора алгоритмов регрессии - либо пенализированная регрессия / лассо-регрессия для линейных данных, либо CART, случайный лес или нейронные сети для нелинейных данных.
Если задача заключается в классификации, то в зависимости от того, размечены ли данные или нет, выбор осуществляется либо из набора алгоритмов классификации при использовании размеченных данных, либо из набора алгоритмов кластеризации при использовании не размеченных данных.
Если данные размечены, то в зависимости от того, имеют ли данные нелинейные характеристики, выбранным алгоритмом классификации будет метод k ближайших соседей (KNN) и метод опорных векторов (SVM) для линейных данных, либо CART, случайный лес или нейронные сети (или глубокие нейронные сети) для нелинейных данных.
Наконец, если данные не размечены, выбор алгоритма кластеризации зависит от того, имеют ли данные нелинейные характеристики.
Выбором алгоритма кластеризации будут нейронные сети (или глубокие нейронные сети) для нелинейных данных или для линейных данных, кластеризация k-средних при известном количестве категорий и иерархическая кластеризация при неизвестном количестве категорий.