CFA - Метод опорных векторов (SVM)
Рассмотрим метод опорных векторов (SVM), один из самых популярных алгоритмов контролируемого машинного обучения, - в рамках изучения количественных методов по программе CFA (Уровень II).
Метод опорных векторов (SVM) является одним из самых популярных алгоритмов в машинном обучении. Это мощный контролируемый алгоритм, используемый для классификации, регрессии и обнаружения выбросов.
Несмотря на свое сложное название, это относительно простой метод и его лучше всего объяснить несколькими картинками.
На левой панели в Иллюстрации 6 представлен простой набор данных с двумя признаками (координатами \(x\) и \(y\)), размеченными как две группы (треугольники и кресты).
Эти бинарные размеченные данные разделены на две хорошо заметные отдельные области, представляющие акции с положительной и отрицательной доходностью в данном году.
Эти две области можно легко разделить бесконечным количеством прямых линий; три из них показаны на правой панели Иллюстрации 6.
Таким образом, данные линейно разделяются, и любая из показанных прямых линий будет называться линейным классификатором (англ. 'linear classifier') - двоичным классификатором, который принимает решение о классификации на основе линейной комбинации признаков каждой точки данных.
Иллюстрация 6. Диаграммы рассеяния и линейное разделение размеченных данных.
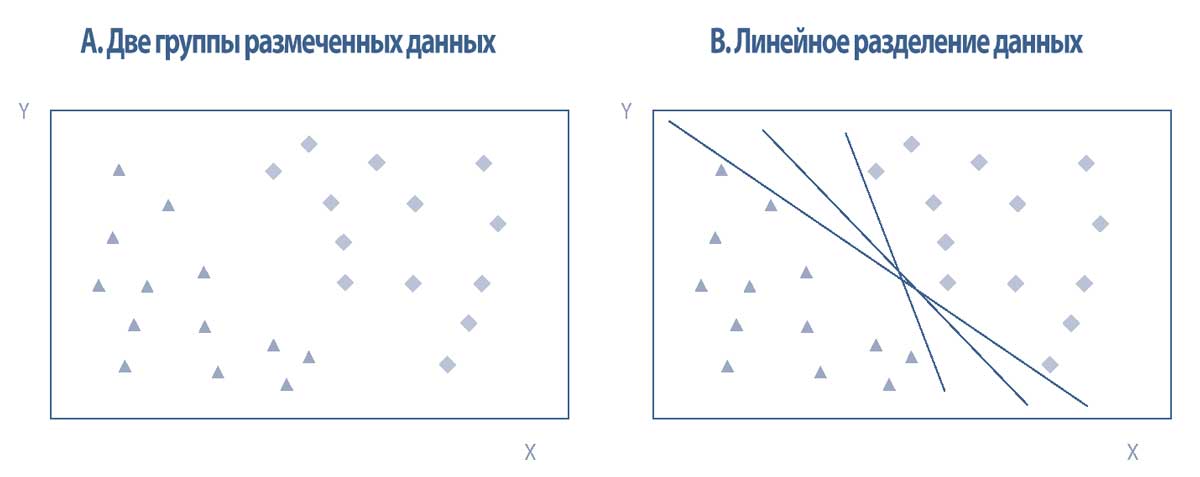
Диаграммы рассеяния и линейное разделение размеченных данных.
При двух измерениях или признаках (\(x\) и \(y\)) линейные классификаторы можно представить как прямые линии.
Наблюдения с \(n\) признаками можно представить в пространстве с \(n\) измерениями. Набор данных будет линейно отделим, если наблюдения можно разделить на две отдельные области по границе линейного пространства.
Общим термином для такой границы пространства является разделяющая n-мерная гиперплоскость, которая при \(n = 1\) называется линией, а при \(n = 2\) называется плоскостью.
Метод опорных векторов (SVM, support vector machine) - это линейный классификатор, который определяет гиперплоскость, которая оптимально разделяет наблюдения на два набора точек данных.
Интуитивно понятная идея алгоритма SVM заключается в максимизации вероятности правильного прогноза (здесь - прогноза того, что наблюдение является треугольником или ромбом) путем определения границы, наиболее удаленной от всех наблюдений.
В Иллюстрации 7 SVM отделяет данные с помощью максимального зазора, где зазор (margin) - это затененная полоса, которая делит наблюдения на две группы.
Прямая линия в середине затененной полосы - это дискриминантная граница или просто граница (boundary), для краткости. Мы видим, что алгоритм SVM вычисляет максимально широкую затененную полосу (то есть полосу с максимальным зазором по обе стороны от границы).
Зазор определяется наблюдениями, наиболее близкими к границе (отмеченные кругом точки) в каждом наборе, и эти наблюдения называются опорными векторами (support vectors).
Добавление дополнительных обучающих данных вдали от опорных векторов не повлияет на границу. Однако в наших обучающих наборах добавление точек данных, которые находятся близко к гиперплоскости, может переместить зазор, изменяя набор опорных векторов.
Иллюстрация 7. Классификатор линейного метода опорных векторов.
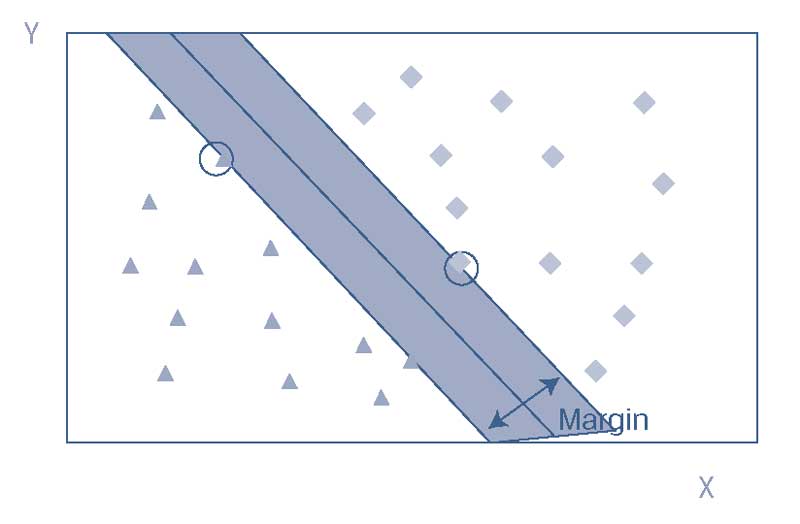
Классификатор линейного метода опорных векторов.
В Иллюстрации 7 SVM прекрасно классифицирует все наблюдения. Однако в реальном мире большинство наборов данных не являются линейно разделимыми.
Некоторые наблюдения могут попасть на неправильную сторону границы и алгоритм SVM неправильно их классифицирует.
Алгоритм SVM решает эту проблему с помощью метода адаптации, называемого классификацией с мягким зазором (англ. 'soft margin classification'), который добавляет штраф к целевой функции для наблюдений обучающего набора, которые неправильно классифицируются.
По сути, алгоритм SVM выберет такую дискриминантную границу, которая оптимизирует компромисс между более широким зазором и более низким штрафом за общее число ошибок.
В качестве альтернативы классификации с мягким зазором, можно применять нелинейный алгоритм SVM путем введения более продвинутых, нелинейных границ разделения. Эти алгоритмы могут уменьшить количество неправильно классифицированных экземпляров в обучающих данных, но они более сложны и, таким образом, склонны к переобучению.
Алгоритм SVM имеет много применений в области управления инвестициями. Он особенно подходит для наборов данных от малого до среднего объема, но обладающих сложностью и высокой размерностью, таких как корпоративная финансовая отчетность или базы данных о банкротстве.
Инвесторы стремятся предсказать банкротства компаний, чтобы выявить акции, которые не следует покупать или к которым следует применять короткие продажи (играть на понижение). Алгоритм SVM может генерировать бинарную классификацию (например, вероятное банкротство против маловероятного банкротства), используя переменные для множества фундаментальных и технических признаков.
Алгоритм SVM может эффективно собирать характеристики таких данных со многими признаками, одновременно оставаясь устойчивым к выбросам и корреляции признаков.
SVM также может использоваться для классификации текста из документов (например, новостных статей, объявлений и годовых отчетов компании) в полезные категории для инвесторов (например, положительное настроение и отрицательное настроение).