CFA - Ансамблевое обучение и случайный лес
Рассмотрим агрегацию алгоритмов машинного обучения, известную как ансамблевое обучение, а также метод случайного леса, - в рамках изучения количественных методов по программе CFA (Уровень II).
Вместо того, чтобы основывать прогнозы на результатах одной модели, почему бы не использовать прогнозы группы (или ансамбля) моделей?
Каждая отдельная модель будет иметь определенный уровень ошибок и будет делать шумные прогнозы. Но, получив средний результат многих прогнозов из многих моделей, мы можем ожидать, что достигнем снижения шума, поскольку средний результат сходится к более точному прогнозу.
Этот метод сочетания прогнозов из коллекции моделей называется ансамблевым обучением (англ. 'ensemble learning'), а сочетание множества алгоритмов обучения известно как метод ансамбля или ансамблевый метод (англ. 'ensemble method').
Ансамблевое обучение обычно дает более точные и более стабильные прогнозы, чем лучшая одиночная модель. На самом деле, во многих престижных соревнованиях по машинному обучению победителем часто оказывается ансамблевый метод.
Ансамблевое обучение можно разделить на две основные категории:
- (1) Агрегация гетерогенного обучения. То есть это различные типы алгоритмов в сочетании с классификатором голосования (механизмом распределения весов на участвующие в ансамбле алгоритмы); или
- (2) Агрегация однородного обучения. То есть это комбинация применения одного и того же алгоритма к различным обучающим данным, которые основаны, например, на бутстрап-агрегировании или бэггинге, который мы обсудим позже).
Классификаторы голосования.
Предположим, что вы некоторое время работали над проектом машинного обучения, выполнили обучение и сравнили результаты нескольких алгоритмов, таких как SVM, KNN и CART.
Классификатор голосования большинством голосов (англ. 'majority-vote classifier') назначает новой точке данных прогнозируемую метку на основании наибольшего числа голосов.
Например, если модели SVM и KNN прогнозируют категорию «превосходная доходность акций», а модель CART прогнозирует категорию «слабая доходность акций», тогда классификатор по большинству голосов выберет «превосходную доходность акций».
Чем больше отдельных моделей вы используете, тем выше будет точность агрегированного прогноза, пока количество моделей не достигнет определенного уровня. Существует оптимальное количество моделей, после которого можно ожидать ухудшения эффективности прогнозирования из-за переобучения алгоритмов.
Хитрость заключается в том, чтобы искать разнообразие при выборе алгоритмов, методов моделирования и гипотез.
Допущение о предельном количестве алгоритмов здесь заключается в том, что если прогнозы отдельных моделей являются независимыми, то мы можем использовать закон больших чисел для достижения более точного прогноза.
Бутстрап-агрегирование (бэггинг).
В качестве альтернативы можно использовать один и тот же алгоритм машинного обучения, но с различными обучающими данными.
Бутстрап-агрегирование (bootstrap aggregating) или бэггинг (bagging, дословно «раскладывание данных по мешкам») - это метод, посредством которого оригинальный обучающий набор данных используется для создания \(n\) новых наборов данных или мешков данных (bags).
Каждый новый набор данных генерируется случайной выборкой с заменой из первоначального обучающего набора. Теперь алгоритм можно обучить на \(n\) независимых наборах данных, которые будут генерировать \(n\) новых моделей.
Затем, для каждого нового наблюдения мы можем агрегировать \(n\) предсказаний, используя классификатор большинства голосов для задач классификации или среднее значение для задач регрессии.
Бэггинг - это очень полезный метод, потому что он помогает улучшить стабильность прогнозов и защищает от переобучения модели.
Случайный лес.
Классификатор случайного леса (англ. 'random forest classifier') - это коллекция большого количества деревьев решений, обученных методом бэггинга.
Например, алгоритм CART обучается с использованием каждого из \(n\) независимых наборов данных (полученных в результате бэггинга) для создания множества различных деревьев решений, которые составляют классификатор случайного леса.
Чтобы получить еще больше индивидуальных прогнозов, можно добиться дополнительного разнообразия в деревьях, случайным образом уменьшая количество признаков, доступных во время обучения.
Таким образом, если каждое наблюдение имеет \(n\) признаков, можно случайным образом выбрать подмножество \(m\) признаков (при \(m < n\)), которое затем будет обработано алгоритмом CART для разделения набора данных на каждом из узлов принятия решений.
Количество подмножеств признаков (\(m\)), количество используемых деревьев, минимальный размер (совокупности точек данных) каждого узла (или листа) дерева и максимальная глубина каждого дерева - все это гиперпараметры, которые можно настроить для повышения точности прогнозирования общей модели.
Для любого нового наблюдения мы позволяем всем деревьям классификатора («случайному лесу») выполнять классификацию большинством голосов, применяя в машинном обучении так называемый принцип «народной мудрости».
Процесс, связанный с построением случайных лесов, имеет тенденцию снижать дисперсию и защищать модель от переобучения. Он также уменьшает уровень шума по отношению к сигналу, поскольку уровень ошибок снижается сразу во всей коллекции немного отличающихся деревьев классификации.
Однако важным недостатком случайного леса является то, что ему не хватает простоты интерпретации, которая есть у отдельных деревьев; в результате этого его относят к алгоритмам «черного ящика» (т.е., алгоритмам, работу которых трудно представить и объяснить).
В Иллюстрации 11 представлены три точечных графика фактических и прогнозируемых дефолтов малых и средних предприятий, построенных на основе двух признаков (\(X\) и \(n\)) - например, прибыльность и леверидж компании соответственно.
Левый график показывает фактические случаи дефолта (легкое затенение) и отсутствие дефолта (сильное затенение), в то время как средний и правый графики показывают прогнозируемые случаи дефолта и отсутствия дефолта (также легкое и сильное затенение соответственно).
Из среднего графика, основанного на традиционной модели линейной регрессии, становится ясно, что модель не может предсказать сложную нелинейную связь между признаками.
И наоборот, правый график, который представляет результаты прогнозирования модели случайного леса, показывает, что эта модель очень хорошо работает, отражая фактическое распределение данных.
Иллюстрация 11. Кредитные дефолты малых и средних заемщиков.
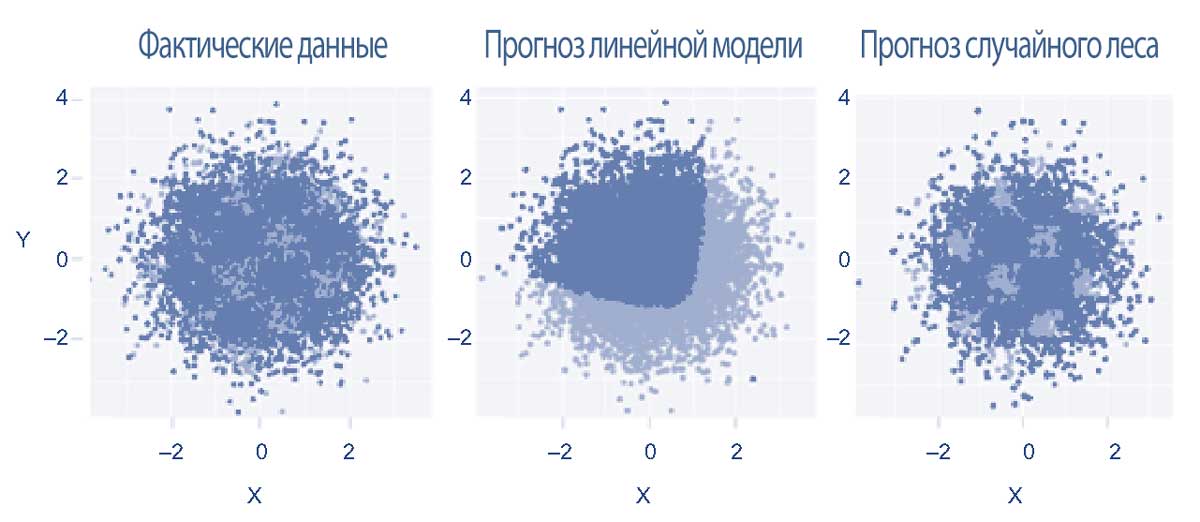
Иллюстрация 11. Кредитные дефолты малых и средних заемщиков.
Источник: Bacham and Zhao (2017).
Ансамблевое обучение со случайным лесом.
Использующий голосование по деревьям классификатора, случайный лес является примером ансамблевого обучения: результат прогнозирования коллекции моделей создает классификации, которые имеют лучшие соотношения сигнал / шум, чем отдельные классификаторы.
Хорошим примером является задача обнаружения мошенничества с кредитными картами на основе данных из открытой базы данных Kaggle.
Здесь данные содержат несколько анонимных признаков, которые могут быть использованы для объяснения того, какие операции были мошенническими.
Сложность анализа вызвана тем, что доля мошеннических операций очень низкая; в выборке из 284,807 операций только 492 были мошенническими (0.17%). Это похоже на поиск иглы в стоге сена.
Применение алгоритма классификации случайного леса с помощью методики избыточной выборки (пропорциональное увеличение наблюдений мошеннических операций в обучающем наборе данных) дает очень хороший результат.
Несмотря на одностороннюю выборку, модель обеспечивает точность (отношение правильно предсказанных мошеннических операций ко всем предсказанным мошенническим операциям) 89% и отзыв (отношение правильно предсказанных мошеннических операций ко всем фактическим мошенническим операциям) 82%.
Несмотря на свою относительную простоту, случайный лес является мощным алгоритмом, имеющим множество инвестиционных применений.
К ним относятся, например, использование основанных на факторах инвестиционных стратегий для распределения активов и выбора инвестиций; прогнозирование того, будет ли IPO успешным, с учетом атрибутов предложения IPO и атрибутов корпоративного эмитента.
В дальнейшем мы рассмотрим мини-кейс модели, основанной на нейронной сети, где представим дополнительную информацию о том, как контролируемое машинное обучение используется для моделирования фундаментального фактора.
Пример 3. Метод опорных векторов (SVM) и метод k ближайших соседей (KNN).
Рэйчел Ли - менеджер портфеля ценных бумаг с фиксированным доходом в компании Zeta Investment Management Company.
Zeta управляет портфелем облигаций инвестиционного класса для небольших, консервативных учреждений и портфелем неинвестиционных (то есть высокодоходных) облигаций для частных лиц, заинтересованных в высокой доходности и высоком росте стоимости.
Оба портфеля могут включать облигации без рейтинга, если характеристики таких облигаций близки к средним характеристикам ценных бумаг соответствующего портфеля.
Ли обсуждает предстоящий выпуск 10-летних облигаций с фиксированным купоном со старшим кредитным аналитиком Марком Уотсоном.
Уотсон считает, что хотя эмитент этих облигаций, Biotron Corporation, не имеет рейтинга для эмиссии, анализ прибыльности, денежного потока, денежных средств и коэффициентов покрытия компании-эмитента позволяет поместить эмиссию между низким инвестиционным рейтингом (Baa3/BBB-) и высоким неинвестиционным рейтингом (Ba1/BB+).
Ли решает использовать методы машинного обучения для подтверждения предполагаемого кредитного рейтинга Biotron Corporation.
- 1. Укажите тип задачи, которую решает Ли.
- 2. Укажите два алгоритма ML, которые Ли могла бы использовать для изучения предполагаемого кредитного рейтинга Biotron Corporation, а затем опишите, как можно применить каждый алгоритм.
Ли решает применить два алгоритма ML. Оба алгоритма явно указывают на высокий неинвестиционный рейтинг. Уотсон утверждает, что, поскольку оба алгоритма ML согласны этим с рейтингом, он уверен в том, что на него следует полагаться.
- 3. Укажите один аргумент в поддержку точки зрения Уотсона.
Решение для части 1:
Ли решает задачу классификации с помощью контролируемого обучения, потому что она должна определить, будет ли предстоящая эмиссия облигаций Biotron классифицироваться как инвестиционный класс или неинвестиционный класс.
Решение для части 2:
Одним из подходящих алгоритмов ML является метод опорных векторов (SVM). Алгоритм SVM представляет собой линейный классификатор, который направлен на поиск оптимальной гиперплоскости, которая разделяет наблюдения на два различных набора данных с помощью разделяющего максимального зазора.
Таким образом, SVM хорошо подходит для задач бинарной классификации, таких как та, с которой столкнулась Lee (инвестиционный класс и неинвестиционный класс).
В этом случае Ли может обучить алгоритм SVM на данных - характеристики (признаки) и рейтинг (цель) - облигаций с низким инвестиционным классом (Baa3/BBB-) и облигаций с высоким неинвестиционным классом (Ba1/BB+).
Затем Ли отметит, на какой стороне зазора лежит новая точка данных (т.е. новые облигации Biotron).
Алгоритм KNN также хорошо подходит для задач классификации, поскольку он классифицирует новое наблюдение, обнаруживая сходства (или близость) между новым наблюдением и существующими данными.
Правило решения для классификации новых облигаций Biotron заключается в том, какая классификация является большинством среди ближайших \(k\) соседних точек данных. Обратите внимание, что \(k\) (гиперпараметр) Ли должна определить заранее.
Решение для части 3:
Если алгоритмы ML дают разную классификацию, классификация с большей вероятностью будет чувствительна к подходу алгоритма к классификации данных.
Поскольку классификация новой эмиссии Biotron кажется надежной для выбранных алгоритмов ML (то есть оба алгоритма согласны с рейтингом), полученная классификация, скорее всего, будет правильной.
Пример 4. Алгоритм CART и ансамблевое обучение.
Лори Ким - менеджер портфеля в Hilux LLC, инвестиционной компании, специализирующейся на высокодоходных облигациях.
Экономика пребывала в рецессии в течение нескольких месяцев, и цены на высокодоходные облигации резко снизились, поскольку кредитные спреды расширились в ответ на слабую макроэкономическую среду.
Ким, однако, считает, что это хорошее время для покупки облигаций. Она рассчитывает получить прибыль, поскольку кредитные спреды достаточно узкие и цены на высокодоходные облигации растут в ожидании восстановления экономики.
Основываясь на своем анализе, Ким считает, что корпоративные высокодоходные облигации с кредитным качеством в диапазоне от B/B2 до CCC/Caa2 являются наиболее привлекательными.
Тем не менее, она должна тщательно выбирать, какие облигации покупать, а каких облигаций следует избегать из-за повышенного риска дефолта, вызванного текущей слабой экономикой.
Чтобы помочь с выбором облигаций, Ким обращается к команде аналитиков данных Hilux. Ким предоставила им исторические данные, состоящие из 19 фундаментальных и 5 технических факторов, по нескольким тысячам эмитентам высокодоходных облигаций и эмиссиям, отмеченным как дефолтные или не дефолтные.
Ким просит аналитиков разработать модель на основе машинного обучения, использующую все необходимые факторы, чтобы получить точную классификацию по двум категориям: дефолт и без дефолта.
Анализ данных предполагает значительную нелинейность в наборе признаков.
- 1. Укажите тип задачи, которую решает Ким.
- 2. Опишите размерность модели, которую Ким просит разработать.
- 3. Оцените, подходит ли модель CART для решения ее проблемы.
- 4. Опишите, как работает модель CART на каждом узле дерева.
- 5. Опишите, как команда может избежать переобучения и улучшить прогнозирующую силу модели.
- 6. Опишите, как команда может использовать ансамблевое обучение для получения более точных прогнозов выбора корпоративных высокодоходных облигаций.
Решение для части 1:
Ким решает задачу классификации, потому что она должна определить, будут ли рассматриваемые облигации в диапазоне кредитного качества от B/B2 до CCC/Caa2 дефолтными или не дефолтными.
Решение для части 2:
При 19 фундаментальных и 5 технических факторах (то есть признаках) размерность модели составляет 24.
Решение для части 3:
Модель CART является алгоритмом для решения задач классификации. Ее способность обрабатывать сложные, нелинейные связи делает ее хорошим выбором для решения стоящей перед Ким задачи.
Важным преимуществом CART является то, что ее результаты относительно просты для визуализации и интерпретации, что должно помочь Ким объяснить свои рекомендации инвестиционному комитету Hilux и клиентам фирмы.
Решение для части 4:
На каждом узле в дереве решений алгоритм выберет определенный признак и отсекающее пороговое значение для этого признака, чтобы разделить размеченные данные и минимизировать ошибку классификации.
Решение для части 5:
Команда аналитиков может избежать переобучения и улучшить прогнозирующую силу модели CART за счет добавления параметров регуляризации.
Например, команда может указать максимальную глубину дерева, минимальную совокупность точек данных в узле или максимальное количество узлов принятия решений.
Итеративный процесс построения узлов будет остановлен при выполнении критерия регуляризации.
В качестве альтернативы, впоследствии можно использовать метод обрезки для удаления частей CART-модели, которые обеспечивают незначительную силу для правильной классификации данных по категориям дефолта и без дефолта.
Решение для части 6:
Команда аналитиков может использовать ансамблевое обучение для объединения прогнозов из коллекции моделей. При этом средний результат многих прогнозов приводит к снижению шума и, следовательно, более точным прогнозам.
Ансамблевое обучение может быть достигнуто за счет агрегации либо гетерогенных методов (алгоритмов различных типов в сочетании с классификатором голосования), либо гомогенных методов (комбинацией одного и того же алгоритма, но с использованием различных данных обучения на основе метода бутстрап-агрегации).
Команда может также рассмотреть возможность создания классификатора случайного леса (то есть коллекции многих деревьев решений), обученного методом бэггинга.