CFA - Дерево классификации и регрессии (CART)
Рассмотрим дерево классификации и регрессии (CART), распространенный и визуально понятный алгоритм контролируемого машинного обучения, - в рамках изучения количественных методов по программе CFA (Уровень II).
Дерево классификации и регрессии (CART, classification and regression tree) - это еще одна распространенная техника контролируемого машинного обучения, которую можно применять для прогнозирования либо категориальной целевой переменной, создавая дерево классификации, либо непрерывной целевой переменной, создавая дерево регрессии.
CART обычно применяется к бинарной классификации или регрессии.
Алгоритм CART будет обсуждаться в контексте упрощенной модели классификации компаний по признаку того, могут ли они увеличить свои дивиденды для акционеров или нет.
Такая классификация требует двоичного дерева: комбинации начального корневого узла (initial root node), узлов принятия решений (decision nodes) и конечных узлов (terminal nodes).
Корневой узел и каждый узел принятия решения представляют одиночный признак (\(f\)) и пороговое отсекающее значение (\(c\)) для этого признака (cutoff value).
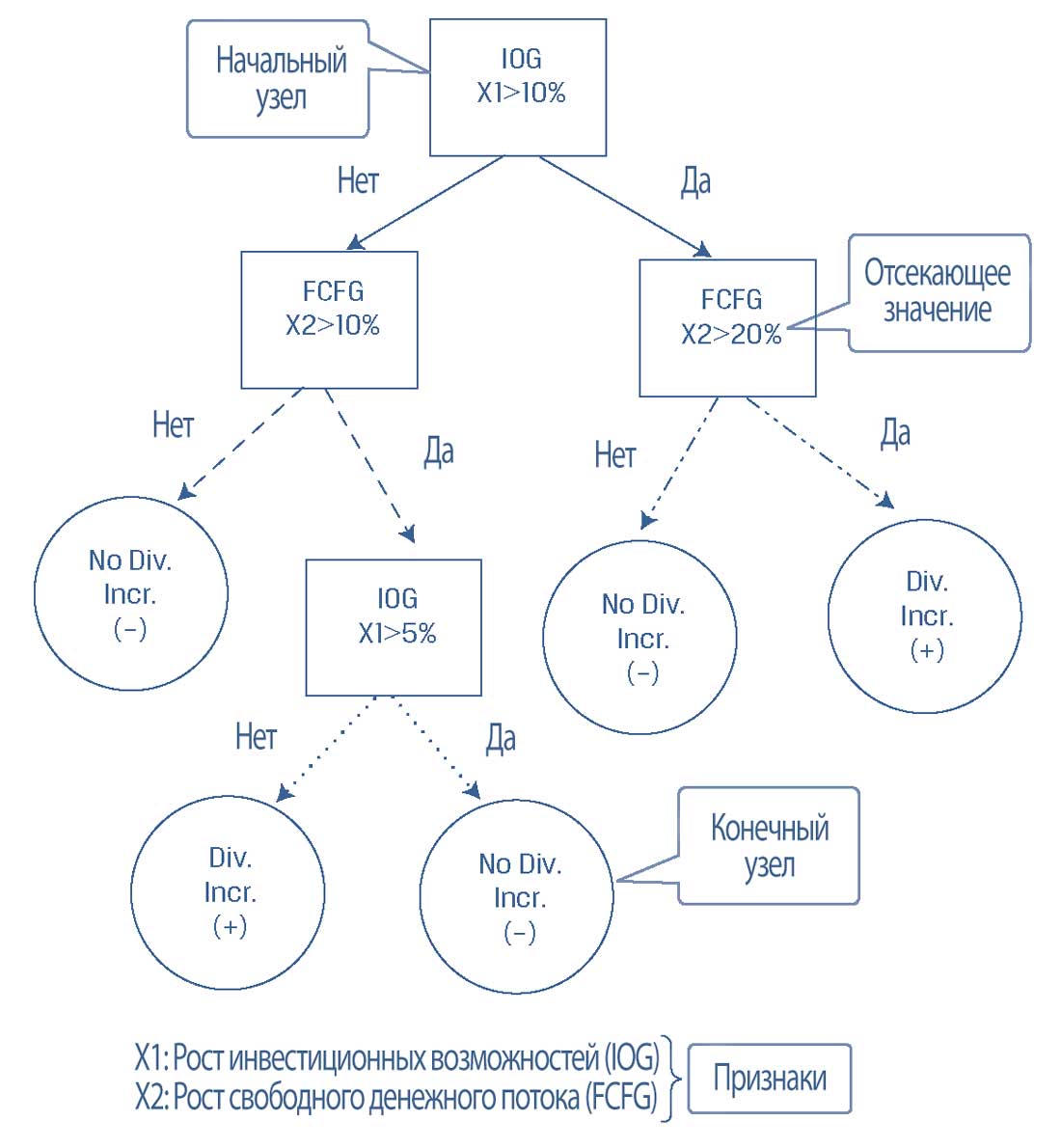
Как показано в Панели A Иллюстрации 9, процесс прогнозирования для новой точки данных мы начинаем с начального корневого узла.
В нашем случае начальный корневой узел представляет признак роста инвестиционных возможностей (IOG, investment opportunities growth), обозначенный как X1, с отсекающим значением 10%.
После исходного корневого узла данные делятся на узлах принятия решений на более мелкие подгруппы, пока не будут образованы конечные (терминальные) узлы, которые содержат прогнозируемые метки.
В этом случае прогнозируемые метки являются либо увеличением дивидендов (Div Incr, метка (+) [плюс]), либо отсутствием увеличения дивидендов (No Div Incr, метка (-) [минус]).
На Панели A Иллюстрации 9 также показано, что если значение признака IOG (X1) превышает 10% (Да), то мы переходим к узлу принятия решения для роста свободного денежного потока (FCFG, free cash flow growth), обозначенного как X2, который имеет отсекающее значение 20%.
Теперь, если значение FCFG не превышает 20% (Нет), то CART предскажет, что эта точка данных принадлежит категории отсутствия увеличения дивидендов «No Div Incr» (-), которая представляет конечный узел.
И наоборот, если значение X2 превышает 20% (Да), то CART предскажет, что эта точка данных принадлежит категории увеличения дивидендов «No Div Incr» (+), которая представляет другой конечный узел.
Важно отметить, что один и тот же признак может появляться в дереве несколько раз в сочетании с другими признаками. Более того, некоторые признаки могут быть актуальны только в том случае, если были выполнены другие условия.
Например, возвращаясь к начальному корневому узлу, если IOG не превышает 10% (X1 < 10%), а FCFG превышает 10%, то IOG снова появляется в качестве другого узла решения, но на этот раз он ниже в дереве и имеет отсекающее значение 5%.
Иллюстрация 9. Дерево классификации и регрессии - дерево принятия решений и разделение пространства признаков.
Панель А. Дерево решений.
Дерево классификации и регрессии - дерево принятия решений.
Панель B. Разделение пространства признаков (X1, X2).
Дерево классификации и регрессии - разделение пространства признаков.
Теперь мы рассмотрим, как алгоритм CART выбирает признаки и отсекающие значения.
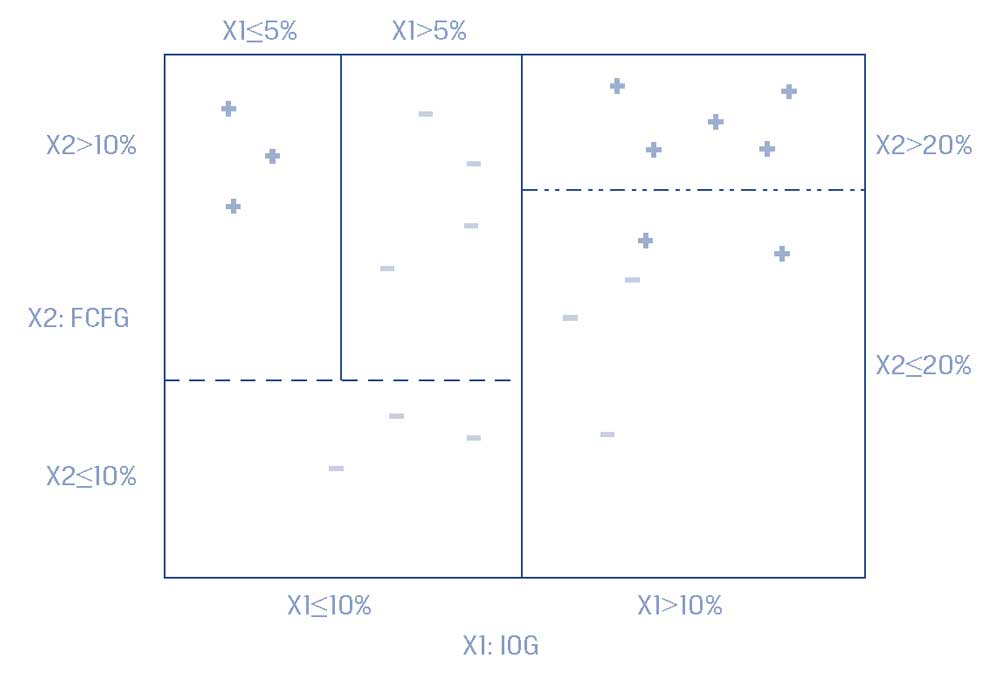
Первоначально, модель классификации обучается на размеченных данных, которые в этом гипотетическом случае представляют собой 10 случаев, когда компании показывают увеличение дивидендов (плюсы) и 10 случаев компаний без увеличения дивидендов (минусы).
Как показано в Панели B Иллюстрации 9, в начальном корневом узле и в каждом узле принятия решения пространство признаков (то есть плоскость, определенная признаками X1 и X2) разделено на два прямоугольника для значений выше и ниже отсекающего значения для конкретного признака, представленного в этом узле.
Это можно увидеть, отметив отдельные закономерности линий, которые исходят из узлов принятия решений в Панели A. Эти же отдельные закономерности используются для разделения пространства признаков в Панели B.
Алгоритм CART выбирает этот признак и отсекающее значение в каждом узле, которое генерирует самое широкое разделение размеченных данных, чтобы минимизировать ошибку классификации (например, по такому критерию, как среднеквадратическая ошибка).
После каждого узла принятия решения разделение пространства признаков становится все меньше и меньше, поэтому наблюдения в каждой группе имеют более низкую внутригрупповую ошибку, чем раньше (до разделения).
На любом уровне дерева, когда ошибка классификации не уменьшается намного в результате следующего разделения, процесс останавливается, текущий узел становится конечным узлом, и категория, к которой принадлежит большинство точек данных в этом узле, присваивается данной точке данных.
Если целью модели является классификация, то результатом прогнозирования алгоритма в каждом конечном узле будет категория с большинством точек данных.
Например, в Панели B Иллюстрации 9 верхний правый прямоугольник пространства признаков, представляющий узлы IOG (X1) > 10% и FCFG (X2 )> 20%, содержит пять меток-плюсов, что является наибольшим числом точек данных этой категории, чем в остальных разделах.
Таким образом, CART предсказал, что новая точка данных (то есть компания) с такими признаками принадлежит категории увеличения дивидендов (метка-плюс).
Однако, если вместо этого новая точка данных имела бы IOG (X1) > 10% и FCFG (X2) < 20%, то алгоритм предсказал бы, что точка данных принадлежит к категории без увеличения дивидендов (метка-минус), представленной нижним правым прямоугольником, в котором 2 метки-плюса и 3 метки-минуса.
Наконец, если целью является регрессия, то результатом прогнозирования на каждом конечном узле является среднее значение размеченных данных.
Алгоритм CART не делает никаких допущений о характеристиках обучающих данных, поэтому, если оставить его без ограничений, он потенциально может идеально обучиться на обучающих данных.
Чтобы избежать такого переобучения, можно добавить параметры регуляризации, такие как максимальная глубина дерева, минимальная совокупность точек данных в узле или максимальное количество узлов принятия решений.
Итеративный процесс построения дерева останавливается после достижения критерия регуляризации.
Например, на Панели B Иллюстрации 9 верхний левый прямоугольник пространства признаков (с узлами X1 < 10%, X2 > 10% и X1 < 5%, и тремя метками-плюсами) может представлять собой конечный узел, возникающий в результате критерия регуляризации, согласно которому минимальная совокупность равна 3.
В качестве альтернативы, регуляризацию может выполнить с помощью метода обрезки, который можно использовать впоследствии, чтобы уменьшить размер дерева. Секции дерева, которые обеспечивают небольшую классифицирующую силу, обрезаются (то есть, вырезаются или удаляются).
По своей итеративной структуре алгоритм CART может раскрыть сложные зависимости между признаками, которые не могут выявить другие модели.
Как показано в Иллюстрации 9, один и тот же признак может появляться несколько раз в сочетании с другими признаками, и некоторые признаки могут быть актуальны, только если были выполнены другие условия.
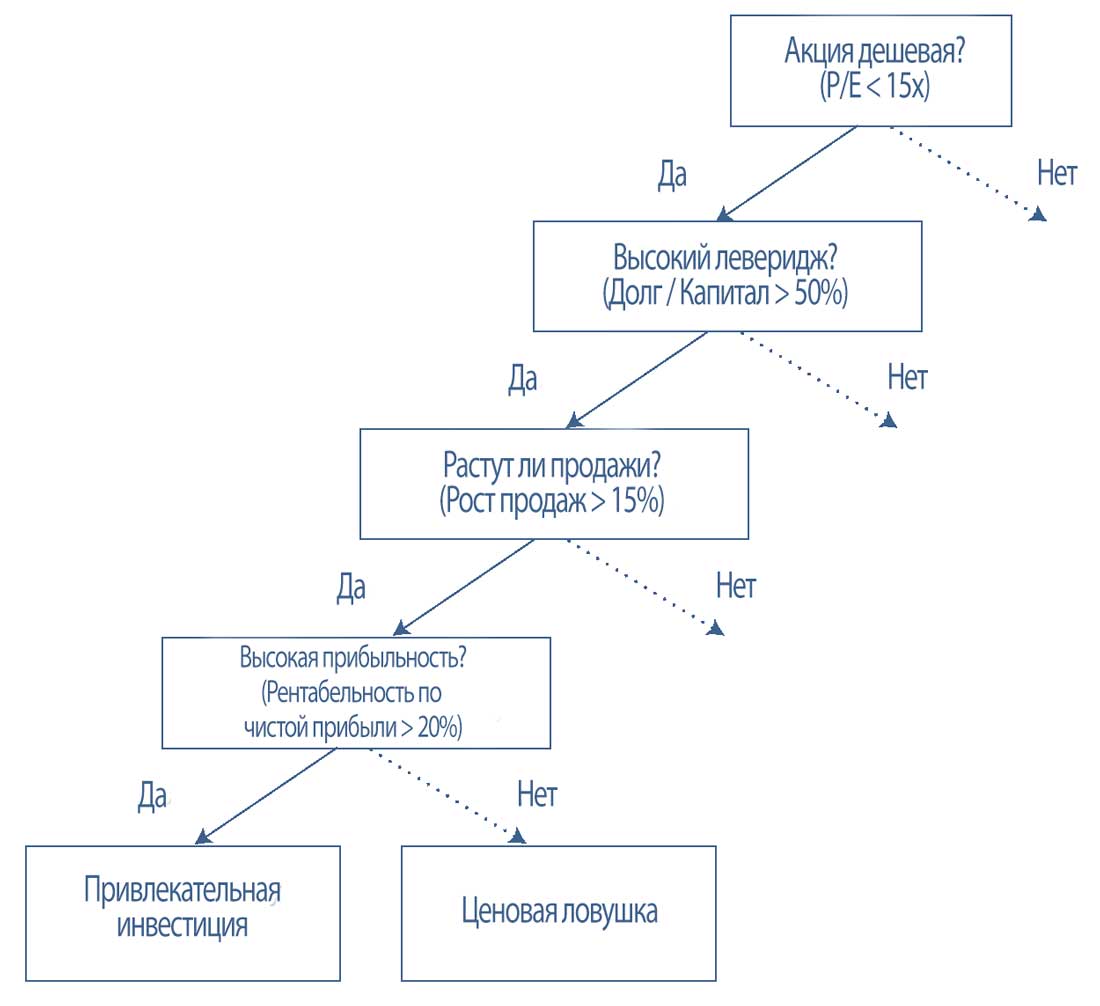
Как показано в Иллюстрации 10, высокая прибыльность является важным признаком для прогнозирования того, является ли акция привлекательной инвестицией или ценовой ловушкой (то есть, инвестицией, которая несмотря на низкую оценку, вероятно, будет убыточной).
Этот признак актуален только в том случае, если акция дешевая: например, в том гипотетическом случае, если P/E меньше 15, а леверидж высокий (отношение долга к общему капиталу > 50%) и продажи растут (рост продаж > 15%).
Иными словами, высокая прибыльность не имеет значения в этом контексте, если акция не дешевая, а леверидж не высок и продажи не растут.
Множественная линейная регрессия обычно терпит неудачу в таких ситуациях, когда связь между признаками и результатом нелинейна.
Иллюстрация 10. Стилизованное дерево решений - привлекательная инвестиция или ценовая ловушка?
Стилизованное дерево решений - привлекательная инвестиция или ценовая ловушка?
Модели CART являются популярными моделями контролируемого машинного обучения, потому что дерево дает визуальное объяснение прогнозирования.
Это выгодно отличает его от других алгоритмов, которые часто считаются «черными ящиками», потому что понять причины их результатов трудно и, таким образом, им трудно доверять.
Алгоритм CART является мощным инструментом для создания экспертных систем для процессов принятия решений. Он может позволить выработать надежные правила, несмотря на шумные данные и сложные связи между большим количеством признаков.
Типичные применения CART в управлении инвестициями включают, среди прочего, включают обнаружение мошенничества в финансовой отчетности, создание обоснованных процессов принятия решений при выборе инвестиций в акции или ценные бумаги с фиксированным доходом, а также упрощение инвестиционных стратегий для клиентов.